GraphQL has become more and more popular among developers to implement APIs (specially frontend developers) as it brings both simplicity and discoverability on the client side. But, what about server side? If you have already worked with Apache Cassandra® you know that designing the proper data model is key. You also know that you need to know your queries very well in order to ensure performance. Is it possible to create an API on top of Apache Cassandra with GraphQL allowing only valid queries? Let's have a look.
GraphQL positioning

Yet another API specification
GraphQL is a query langage created in 2012 by Facebook. They used it multiple years in production before giving it to the open source community in July 2015. Some web giants adopted it right away like Pinterest but the big shift happened in September 2016 when Github announced they were embracing the technology. Most developers are now accustomed to developing REST API using OpenAPI standard (swagger-ish). What makes GraphQL so appealing? The main advantages are the following
- GraphQL is strongly typed : You can validate queries before firing them against the server. It allows the development of tools like
GraphiQLto help you interact with your API - GraphQL is less verbose : Clients will ask exactly for the data they need. Requests are forged on client side where they specified which data they need. Servers will send back the expected Payload not only filtering unwantering attributes but also a hierachical chunk of objects. Not only can you limit the number of data for each entity but you can also limit the number of requests by providing everything as a tree in a single call. Those features are really keen on mobile development or any use where the bandwith or data transfer are important.
- Your API is discoverable. That means that the client can ask the API to describe itself, to communicate about the entities and the functions available. You don't need some contract, the client can discover it at runtime.
But, GraphQL, like others technologies, is not a silver bullet and some pain points remain :
- There is a single endpoint to access all the operations. This could be both an advantage for the simplicity but this is mostly a drawback because this does not allow versioning.
- Even if strongly typed (which could allows all kinds of code generation engines) the tooling is limited. Technology is young. The schema is quite complex to comprehend, we wiil see that later in this article
- As each query may be unique and hierarchical there is no caching mechanism in place on the server side.
- There were no asynchronous operations previously, but this is becoming possible with last specification version
In the Advocates team we have been working with multiple formats and technologies to expose services like REST, gRPC, oData or GraphQL for our reference application KillrVideo. While GraphQL looks promising, it is not a silver bullet and should only be used with proper use cases. Our team had a talk on the subject you can view the slides and video. Here is our take on this topic:
- GraphQL seems relevant when the network and bandwith matter (mobile) as there will be less calls and data on the wire,
- GraphQL seems relevant when you need a typed schema (less flexibility) and some kind of contract between you and your consumer or maybe you don't know your consumer (public API)
- GraphQL seems relevant when you have a highly connected or hierarchical data. Relations and traversal can be retrieved as a single query
- GraphQL seems relevant when you need to aggregate multiple data sources (mashup).
- For CRUD operations, plain old REST is still the way to go
- For streaming, asynchronous and action/command oriented API, gRPC is our best choice
Enough with the chit chat, let's get our hands dirty.
Sample Application

KillrVideo Application and Data Access Object (DAO)
Without surprise we will leverage our reference application Killrvideo. We will focus on read and wite operations for our Comments section that can be found here. Here is a simplified of the version we will leverage:
public interface CommentDseDao {
/** Provide videoid and paging information to retrieve a set of comments. */ ResultListPage findCommentsByVideoId(QueryCommentByVideo query);
/** Provide userid and paging information to retrieve a set of comments. */ ResultListPage resultComments = findCommentsByUserId(QueryCommentByUser query);
/** Insert new comment on all expected tables from a web bean. */ void insertComment(Comment myComment);
// [..]
}
GraphQL Schema
The first thing to do is to create the GraphQL schema defining all enties and available operations. There are two types of services QUERY and MUTATIONS. Mutations seem familiar right? It's indeed the exact same notion we find with Apache Cassandra. The key takeaway here is to notice by default everything is forbidden and only allowed operations declared in the schema will be available. THIS, is a perfect match for Cassandra usage where we don't allow users to execute forbidden queries like select * from myHugeTable and make our database blow up by allowing for a full table scan.
# Killrvideo GraphQL API
schema {
query: Query
mutation: Mutation }
# Searches and read-only operations on KillrVideo Keyspace #-------------------------------------------------------------
type Query {
# Search in table comment_by_video, eventually with Pagination.
getVideoComments(videoid: String!, commentid: String, pageSize: Int , pageState: String): ResultPageCommentGQL! # Search in table comment_by_user, eventually with Pagination.
getUserComments(userid: String!, commentid: String, pageSize: Int , pageState: String): ResultPageCommentGQL!
}
# Operation that will updated data in DB
#------------------------------------------------------------- type Mutation {
# Add a comment for dedicated video and known user.
commentOnVideo(commentid: String!, videoid: String!, userid: String!, text: String!): CommentGQL!
}
For now we will have to declare the entities used as input and outputs. There are a number of types available in the schema (Scalar, Object, Interface, Union, InputObject, Enum) and you can details here.
# Represent a video comment in GraphQL format type CommentGQL {
#Unique identifier for a user (tech id) commentid: ID!
# Unique identifier for a user (required) userid: String!
# Unique identifier for a video (required) videoid: String!
# Text of the comment comment: String
# Insertion Date
dateOfComment: String } type ResultPageCommentGQL {
listOfResults: [CommentGQL]!
nextPage: String
}
Spring Boot and GraphQL
With this GraphQL schema we are all set to start implementing. The same schema can be used with many different languages. In our sample we will use Java and graphql-javaframework. Instead of mapping everything manually we will leverage on relevant spring-boot-starter and define expected beans. First thing to do is to declare the following dependencies in your pom.xml file.
<!-- GraphQL -->
<dependency>
<groupId>com.graphql-java</groupId>
<artifactId>graphql-java</artifactId>
</dependency>
<dependency>
<groupId>com.graphql-java</groupId>
<artifactId>graphql-java-tools</artifactId>
</dependency>
<!-- SpringBoot -->
<dependency>
<groupId>com.graphql-java</groupId>
<artifactId>graphql-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>com.graphql-java</groupId>
<artifactId>graphiql-spring-boot-starter</artifactId> <!-- += We will speak about it in a minute -->
</dependency>
Define the associated POJO :
public class CommentGQL implements Serializable {
private static final long serialVersionUID = -4032110812123661790L;
protected String userid;
protected String videoid;
protected String comment;
protected String commentid;
private Date dateOfComment;
// getters, setters
}
public class ResultPageCommentGQL {
private List < CommentGQL > listOfResults = new ArrayList<>();
private String nextPage;
// getters, setters
}
Define the expected 2 beans com.coxautodev.graphql.tools.GraphQLMutationResolver and com.coxautodev.graphql.tools.GraphQLQueryResolver. We use the method names declared in the schema file. From there this is simply mapping parameters and invoking the DAO. Some parts of code are simplifier, full source code can be found here.
@Component
public class KillrvideoMutation implements GraphQLMutationResolver {
@Autowired
private CommentDseDao commentDseDao;
public CommentGQL commentOnVideo(String commentid, String videoid, String userid, String text) {
// Ommited parameters validation
Comment newComment = new Comment(); // Populating bean
commentDseDao.insertComment(newComment);
return new CommentGQL(newComment);
}
}
@Component
public class KillrvideoQuery implements GraphQLQueryResolver {
@Autowired
private CommentDseDao commentDseDao;
public ResultPageCommentGQL getVideoComments (String videoid, String commentid, int pageSize, String pageState) {
QueryCommentByVideo qcbv = new QueryCommentByVideo();
// Mapping ommited
ResultListPage resultComments = commentDseDao.findCommentsByVideoId(qcbv);
ResultPageCommentGQL result = new
ResultPageCommentGQL(); resultComments.getPagingState().ifPresent(result::setNextPage);
result.setListOfResults(
resultComments.getResults().stream()
.map(CommentGQL::new)
.collect(Collectors.to
List()));
return result;
}
public ResultPageCommentGQL getUserComments (String userid, String commentid, int pageSize, String pageState) {
QueryCommentByUser qcbu = new QueryCommentByUser();
// Mapping ommited ResultListPage resultComments = commentDseDao.findCommentsByUserId(qcbu); ResultPageCommentGQL result = new ResultPageCommentGQL(); resultComments.getPagingState().ifPresent(result::setNextPage); result.setListOfResults(
resultComments.getResults().stream()
.map(CommentGQL::new)
.collect(Collectors.toList()));
return result;
}
}
We have now everything we need to make it work. If you look at the github repository you will find some boiler plate code like a main and configuration loading here and there. To start the application, execute the standard mvn spring-boot:run. Your api is now started and is available at http://localhost:8083/gql . The API can be invoked from clients but there is still no user interface to test.
GraphiQL
GraphiQL is a graphical interactive in-browser GraphQL IDE. It allows you to discover existing GraphQL endpoints and fire sample requests. To enable this interface in our sample we added the dependency graphiql-spring-boot-starter in our pom.xml. You can now access the api at http://localhost:8083/gql/graphiql. On the right hand side of the screen you can see the different functions we define, the entities but also the comment we added in the schema file.
Testing our Application
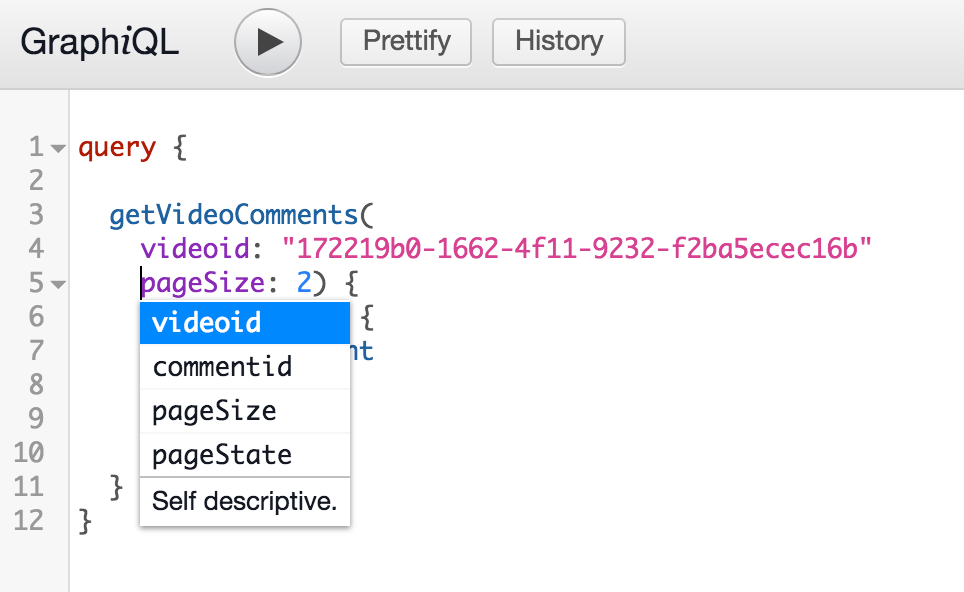
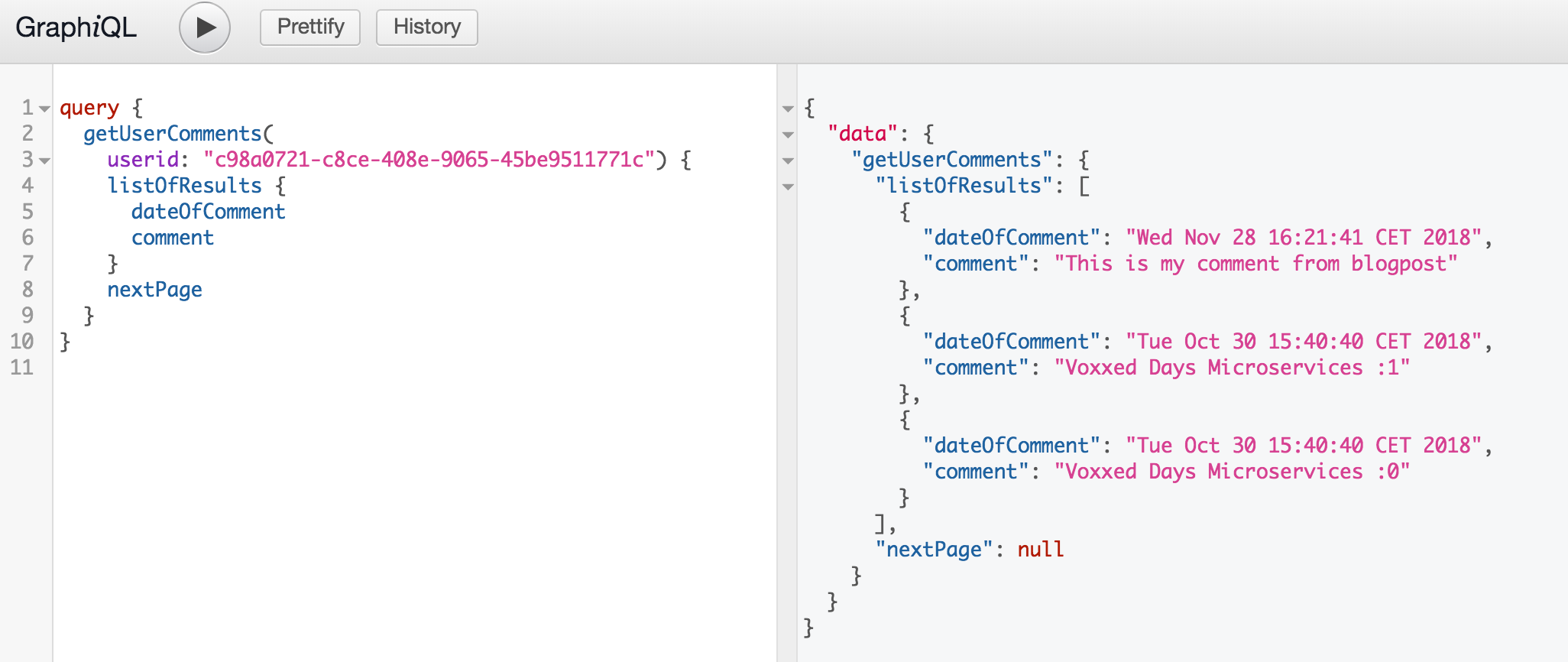
Testing is now straight forward, build your queries and execute using the run button at the top of the page. You will notice that there is some autocompletion in the panel on the right if you use the shortcut CTRL+SPACE.
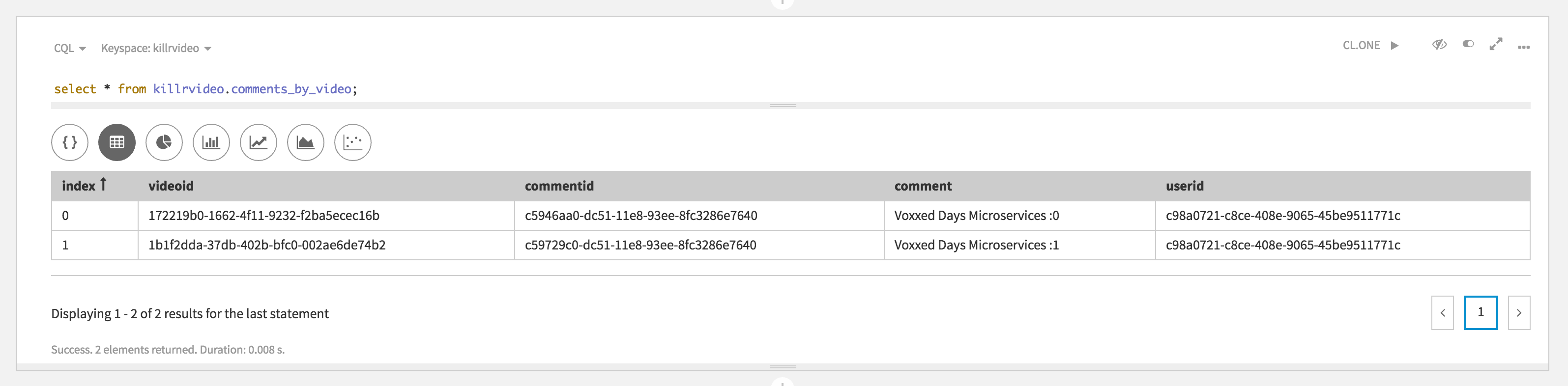
userid and videoid. To do so we use DataStax Studio and query the table comments_by_video. You can see in the picture that we can use the existing video id 172219b0-1662-4f11-9232-f2ba5ecec16b and the existing userid : c98a0721-c8ce-408e-9065-45be9511771c
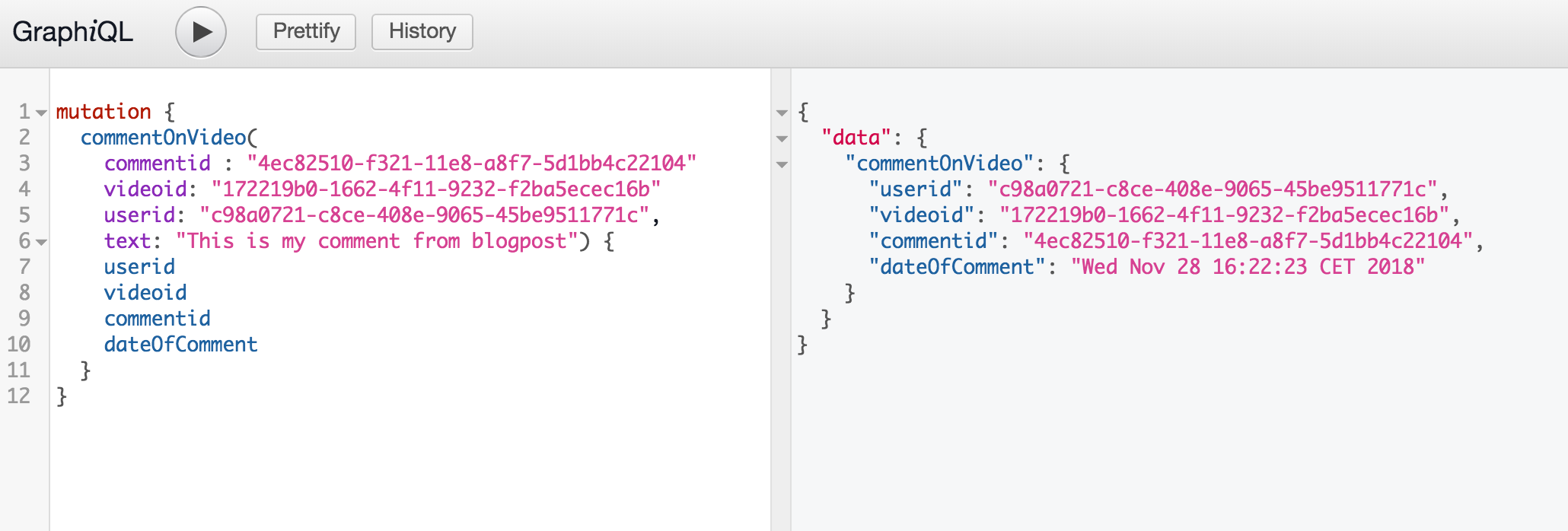
Let's create a mutation to insert a comment using the schema. commentid is expected to be a valid TimeUUid. To generate one you can either execute the following test in your favourite IDE System.out.println(UUIDs.timeBased());or use cqlsh or DataStax Studio with the following command : SELECT now() FROM killrvideo.comments_by_video LIMIT 1
Ok, now query the list of comments for our user c98a0721-c8ce-408e-9065-45be9511771c and observe the expected 3 comments. We only needs 2 attributes which are the date of the comment and the text so let's filter :
Takeaways
We have seen that GraphQL can be easily used with a Cassandra backend.You can't implement CRUD operations, but you can allow queries you want to enforce good performance on your Cassandra clusters.
Happy coding!



