
Since entering the generative AI and retrieval-augmented generation (RAG) space, DataStax has launched several products that support application development, including JVector for vector storage and Langflow, a low-code visual tool for rapid GenAI development.
With the introduction of these tools, we’ve discovered new testing challenges that go with them. The rapid evolution of GenAI apps necessitates thinking about how to do this testing in a new way, and assessing the semantic performance of these modern application stacks was a problem outside of the scope of our existing performance tests.
As the scope of RAG implementations expands and diversifies, evaluating their accuracy, relevance, and overall quality becomes increasingly complex. At DataStax, we’ve opted to integrate the RAGChecker framework with our own suite of products for our semantic testing efforts due to its comprehensive capabilities, adaptability, and alignment with our strategic goals.
In this post, we'll describe the challenges that led us to build a new tool that would meet our need for semantic testing, and how we met that need by integrating our own technology stack with the RAGChecker framework, as well as showing you how the results lead to a better understanding of RAG applications and how they can be improved.
Challenges of semantic testing for GenAI applications
So what is semantic testing and why do we need to worry about it, beyond our usual performance testing scope? Semantic testing for RAG applications assesses the accuracy, relevance, and completeness of responses generated by large language models (LLMs).
This falls outside of the typical realm of testing performance features such as latency and throughput and gets to testing what’s at the heart of AI applications, and the very thing that sets them apart from standard applications that have a binary correct or incorrect result. Semantic testing is designed to test the qualities of the LLM responses; the logic and meaning behind the replies that an LLM will generate. However, several challenges complicate this task:
-
Diverse RAG architectures - RAG systems range from simple prompt augmentations to complex multi-stage pipelines incorporating transforms, scoring, and ranking.
-
Dynamic landscape - The terminology, methods, and tools for evaluating RAG systems are evolving rapidly.
-
Human involvement - While automation is desirable, human evaluation is often required to cross-validate results.
-
Complex metrics - Traditional metrics like precision and recall are insufficient for capturing the nuances of semantic accuracy in RAG systems.
To address these challenges, we needed a testing framework that provides fine-grained diagnostics, supports dynamic datasets, and aligns with our GenAI product stack.
Why RAGChecker?
After testing several potential fits, RAGChecker emerged as the best choice for several reasons.
Fine-grained evaluation
RAGChecker goes beyond surface-level response analysis by evaluating claim-level entailment. It breaks down generated responses into "claim triplets" (e.g., subject-predicate-object) and compares them against ground-truth answers and retrieved context. This granular approach ensures:
-
Accurate detection of hallucinations
-
Measurement of faithfulness and noise sensitivity
-
Assessment of context utilization
Support for dynamic contexts
Unlike static testing frameworks, RAGChecker supports dynamic and user-defined datasets, enabling us to evaluate performance across diverse scenarios, from zero context to noisy and accurate contexts.
Diagnostic metrics for modular testing
RAGChecker provides distinct metrics for both retrieval and generation components:
-
Retriever metrics - Claim recall and context precision assess how well the retriever sources relevant information.
-
Generator metrics - Faithfulness, noise sensitivity, and hallucination rates evaluate the quality of generated responses.
These metrics enable us to pinpoint issues at the modular level, facilitating targeted improvements.
Alignment with our GenAI stack
RAGChecker integrates seamlessly with our GenAI ecosystem, which includes tools like Langflow, Astra DB, and JVector. This compatibility enables us to:
-
Automate context loading and embedding generation
-
Perform end-to-end testing of RAG pipelines with minimal manual intervention
-
Benchmark DataStax offerings against competitors
Most importantly, this alignment enabled us to develop the testing framework we describe in the next section: a combination of RAGChecker with Langflow.
RAGChecker + Langflow integration
The RAGChecker evaluator generates response claim triplets from the ground-truth claims, the LLM response, and the contextual data provided to the LLM. It then evaluates these matrices of claim triplets against each other to generate a detailed set of metrics to provide insight into the strengths and weaknesses of the various components in the application under test.
RAGChecker internally uses a configurable LLM provider such as OpenAI or Ollama to perform these claim-level entailment checks.
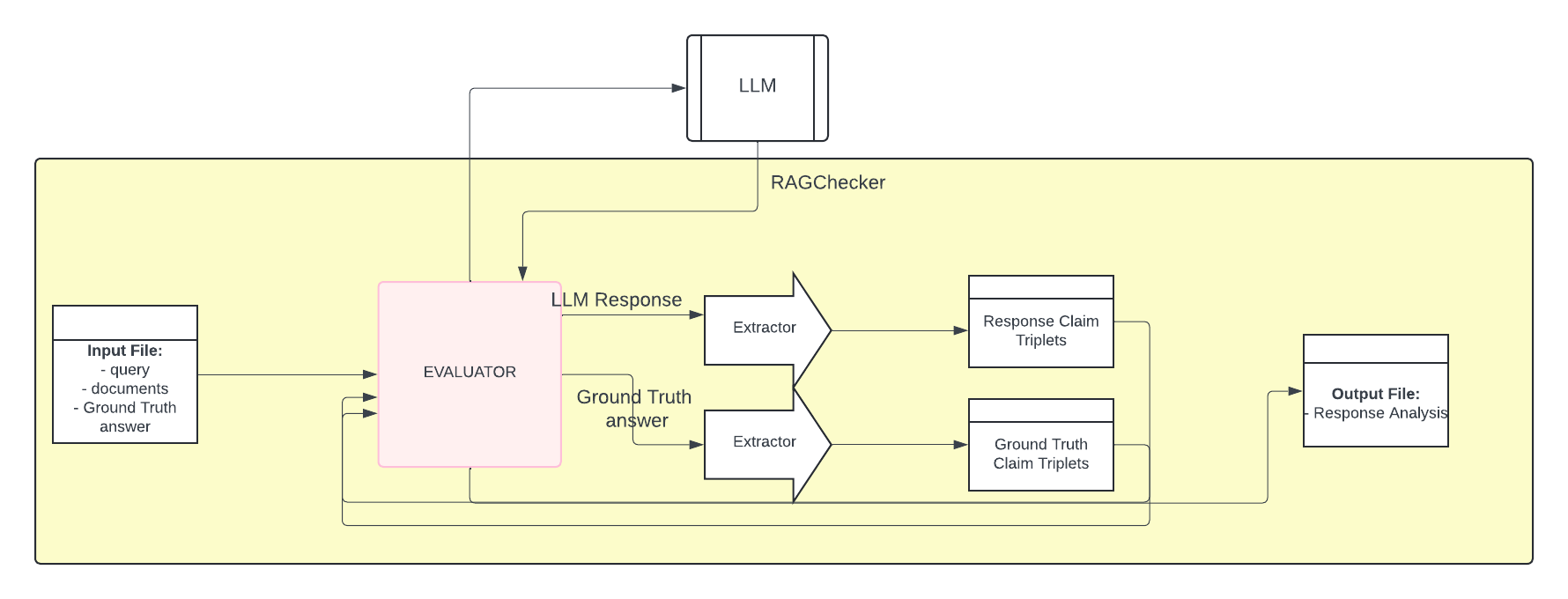 Figure 1: RAGChecker framework accepts as input a file containing multiple samples where each sample in our benchmark dataset in the format of a tuple ⟨q, D, gt⟩ representing query, documents, and ground-truth answer, where query is the input question to a RAG system, documents form the database providing possible context and are processed into chunks with the same number of tokens, and ground-truth answer is a complete and correct answer for the input question.
Figure 1: RAGChecker framework accepts as input a file containing multiple samples where each sample in our benchmark dataset in the format of a tuple ⟨q, D, gt⟩ representing query, documents, and ground-truth answer, where query is the input question to a RAG system, documents form the database providing possible context and are processed into chunks with the same number of tokens, and ground-truth answer is a complete and correct answer for the input question.
Note that within this sequence of operations, all of the data, including the LLM response, are provided as inputs to the RAGChecker process. This evaluation presupposes that the data prepared has been acquired through using a RAG application to provide context and response but does not differentiate between that situation and, for example, data prepared by hand.
This leads us to our current framework, an integration with Langflow that lets us vary the components of the RAG application prior to RAGChecker evaluation in order to evaluate the impact of these changes on the overall semantic scoring of the application. First, let’s take a look at what the integrated architecture looks like:
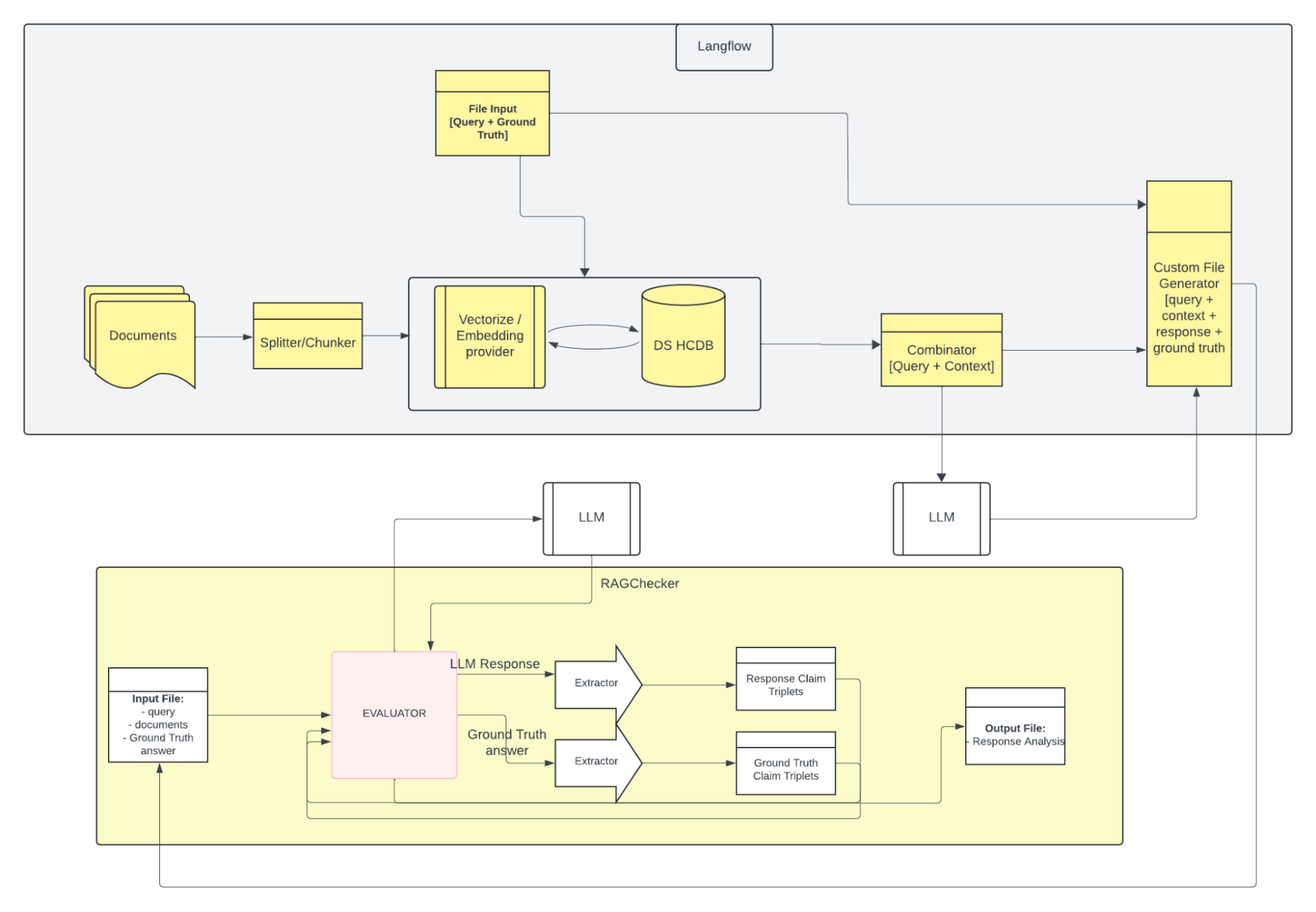 Figure 2: Langflow and RAGChecker integration where Langflow is used to generate and store the embeddings for the documents associated with the dataset in question. Embeddings are then retrieved and used to generate the input file to RAG Checker for comparison with the baseline results.
Figure 2: Langflow and RAGChecker integration where Langflow is used to generate and store the embeddings for the documents associated with the dataset in question. Embeddings are then retrieved and used to generate the input file to RAG Checker for comparison with the baseline results.
Inputs and outputs
We start with a dataset consisting of, at a minimum, the following data:
-
Queries
-
Ground truth responses
-
Contextual information
{
"query": "What's the longest river in the world?",
"gt_answer": "The Nile is a major north-flowing river in northeastern Africa…”,
"context": [
{
"text": "Scientists debate whether the Amazon or the Nile is the longest river in the world…”,
"text": "The Nile River was central to the Ancient Egyptians' rise…",
…
}
]
}The contextual information for each record is then extracted and sent to Langflow via API, where it’s chunked and stored in the vector store used by the RAG application under test. The questions are then extracted from the dataset and sent to Langflow, where augmentation takes place using the contextual data previously stored. The augmented query is then proposed with context to the LLM being used by the RAG application, and the response is stored in Astra DB as a unique record consisting of the query, the ground truth response, and the related contextual information.
{
"query": "What's the longest river in the world?",
"gt_answer": "The Nile is a major north-flowing river in northeastern Africa…”,
"response": "The longest river in the world is the Nile, stretching approximately 6,650 kilometers…",
"retrieved_context": [
{
"text": "Scientists debate whether the Amazon or the Nile is the longest river in the world…”,
"text": "The Nile River begins at Lake Victoria…",
…
}
]
}RAGChecker then leverages a configured method, typically LLM, to compare each claim from response against the set of ground truth claims and vice versa, as well as comparing these claims against the contextual data to generate a set of comparisons that can be qualified as entailments, neutral, or contradictions.
"answer2response": ["Entailment","Neutral",...], "response2answer": ["Entailment","Contradiction",...] "retrieved2response": ["Entailment","Neutral",...] "retrieved2answer": ["Entailment","Entailment",...]
The outputs of the previous step can be thought of as a group of matrices comparing the claims of each participant against the claims of the others.
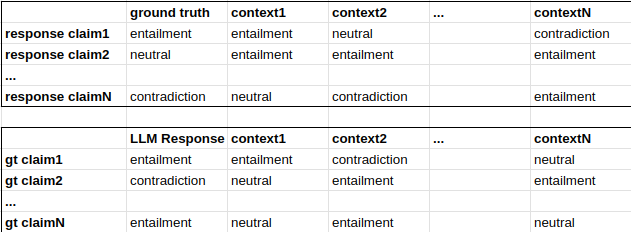
Finally, the matrix of claim relationships generated in the previous steps is used to generate a set of metrics evaluating the response of the RAG application given the ground truth and context provided.
"metrics": {
"overall_metrics": {
"precision": 72.2, ← The proportion of correct claims in all response claims.
"recall": 65.3, ← The proportion of correct claims in all ground-truth answer claims
"f1": 68.5 ← The harmonic average of precision and recall
},
"retriever_metrics": {
"claim_recall": 83.3, ←How many claims made in the ground-truth answer are covered by retrieved chunks
"context_precision": 100.0 ←A measure of the correctness of retrieved context chunks
},
"generator_metrics": {
"context_utilization": 75.0, ←The proportion of response entailments supported by retrieved context
"noise_sensitivity_in_relevant": 16.7, ← level of generator sensitivity to relevant noise
"noise_sensitivity_in_irrelevant": 0.0, ← level of generator sensitivity to irrelevant noise
"hallucination": 11.1, ← The proportion of Incorrect claims that are not entailed in any retrieved chunk
"self_knowledge": 11.1, ← The proportion of correct claims not entailed by any chunk
"faithfulness": 77.8 ← describes how faithful the generator is to the provided context
}
}Room to grow
The key feature to note about the integration of Langflow is that because of the low-code, flexible nature of the framework, the majority of the components in the RAG application can be altered and configured without making any actual code changes. For example, here is the verbatim command line that can be used to load contextual data using a text splitter component to generate chunks of size 1000 with an overlap of 20 and a newline separator, and store the results in a collection named “rag_context”:
python3 load_context.py --context_file_path=./msmarco.json --context_column=context --endpoint=context --format=json --tweaks="{\"SplitText-z4ecM\": {\"chunk_overlap\": 20, \"chunk_size\": 1000, \"separator\": \"\n\"},\"AstraDB-THQ8E\": {\"collection_name\": \"rag_context\"}}"And here is the command to generate chunks of size 400 with an overlap of 100 and a tab separator, and store the results in a collection named “rag_context_400”:
python3 load_context.py --context_file_path=./msmarco.json --context_column=context --endpoint=context --format=json --tweaks="{\"SplitText-z4ecM\": {\"chunk_overlap\": 100, \"chunk_size\": 400, \"separator\": \"\t\"},\"AstraDB-THQ8E\": {\"collection_name\": \"rag_context_400\"}}"Similarly, the flexibility of this framework enables us to vary components such as the vector store, embedding provider, LLM, and persistent message store, all with minimal actual changes. Indeed, even when major changes are involved, the modular nature of this integration allows for the endpoint to be specified at runtime, so that a cutover to a different flow deployed to Langflow is a trivial change.
What’s the bottom line?
Given all of the above, what does this mean for semantic testing of RAG applications? It means that we’ve developed a way to iterate over the choices made and the components deployed as parts of a RAG application and modify those components at runtime to come up with a repeatable and detailed set of metrics that enable us to know in detail the effects of modifying the configuration of any one of those components. As an example, consider the following illustration:
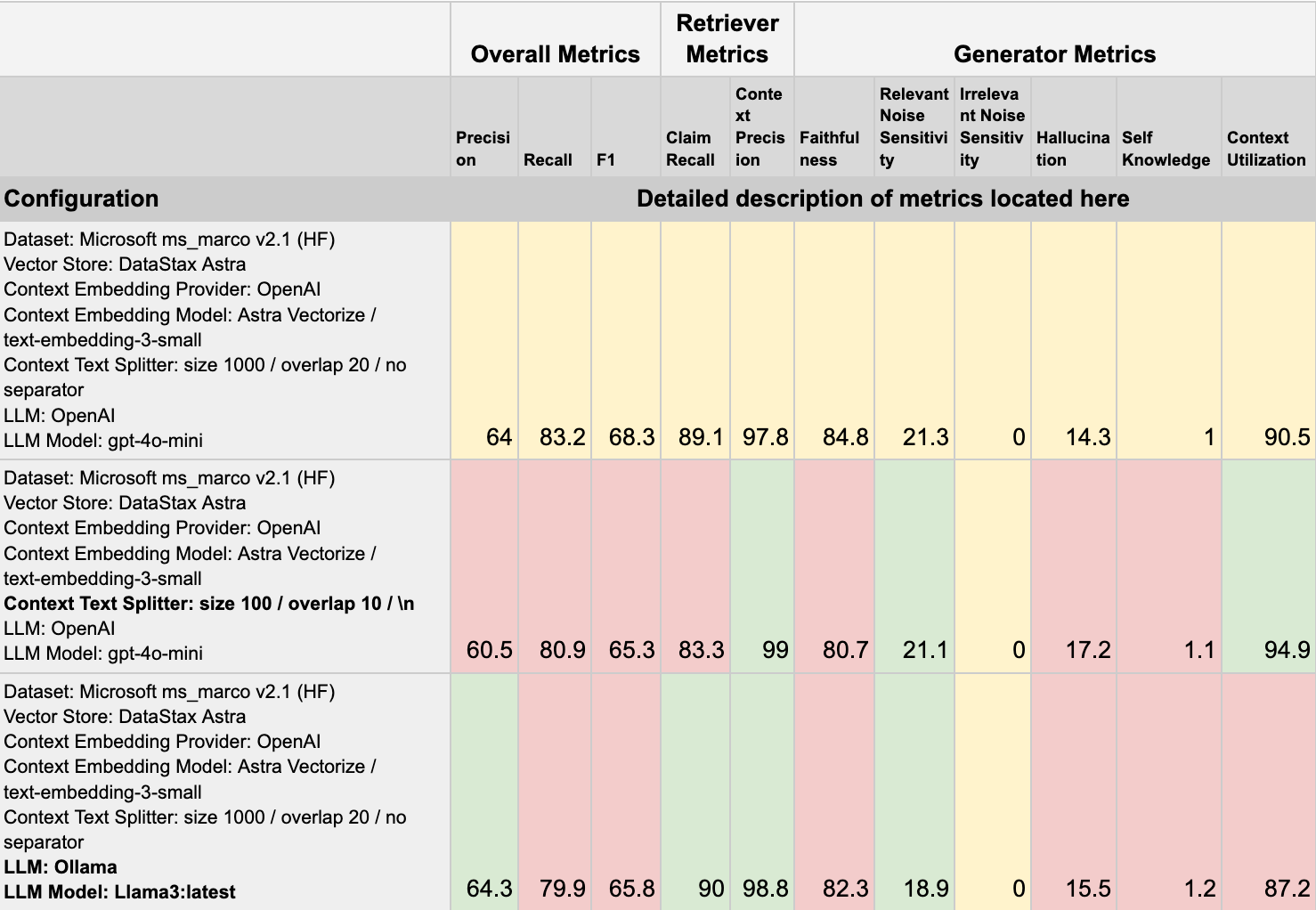
This displays the differences between 3 different runs of the same RAG application, with variances in the splitter used for storing context chunks in the second run and a change in the LLM for the third run. This illustrates how the application can be configured, both at the fine grained level such as text chunking, and at a grosser level by changing the LLM used, to produce detailed metrics allowing the end user to fine tune their application to achieve the desired semantic qualities.
By implementing a semantic testing strategy with RAGChecker and Langflow, we’ve established a systematic and repeatable approach to evaluating the effectiveness of RAG applications using clear and understandable scoring metrics.
Here are a couple of screenshots of what the logic discussed in this post looks like in the Langflow development environment:
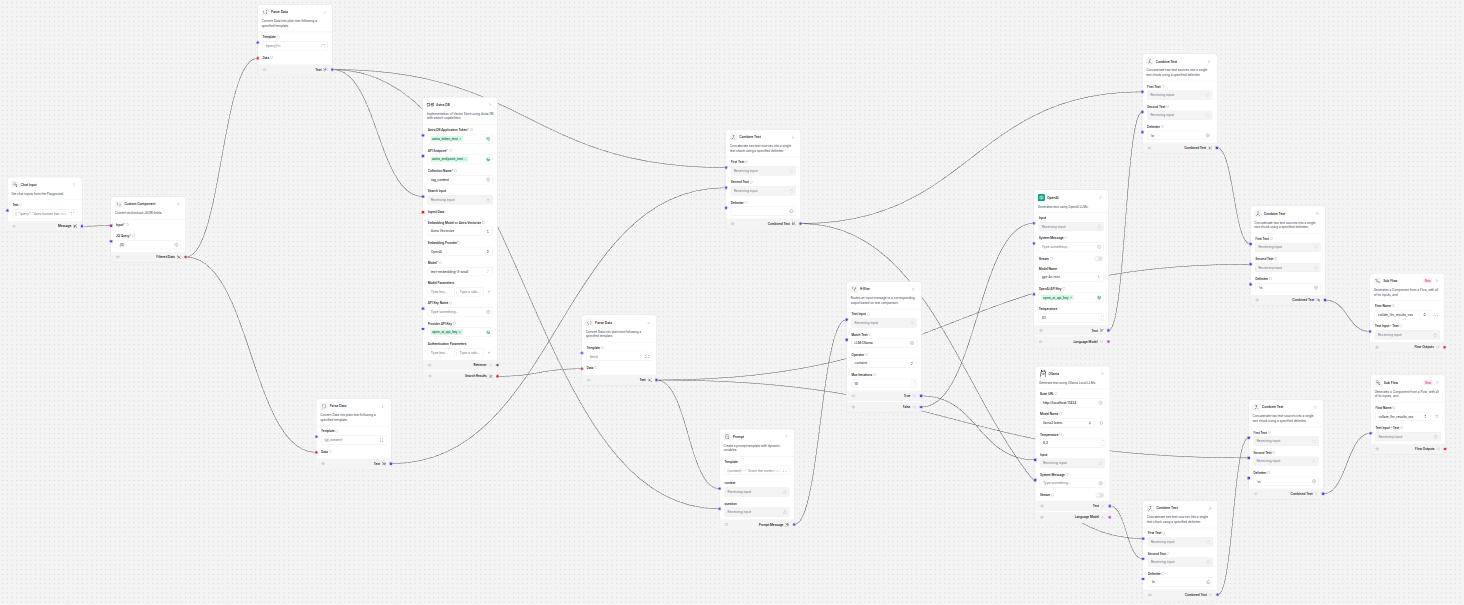 Figure 3: Langflow integration main module with conditional logic controlling choice of LLM
Figure 3: Langflow integration main module with conditional logic controlling choice of LLM
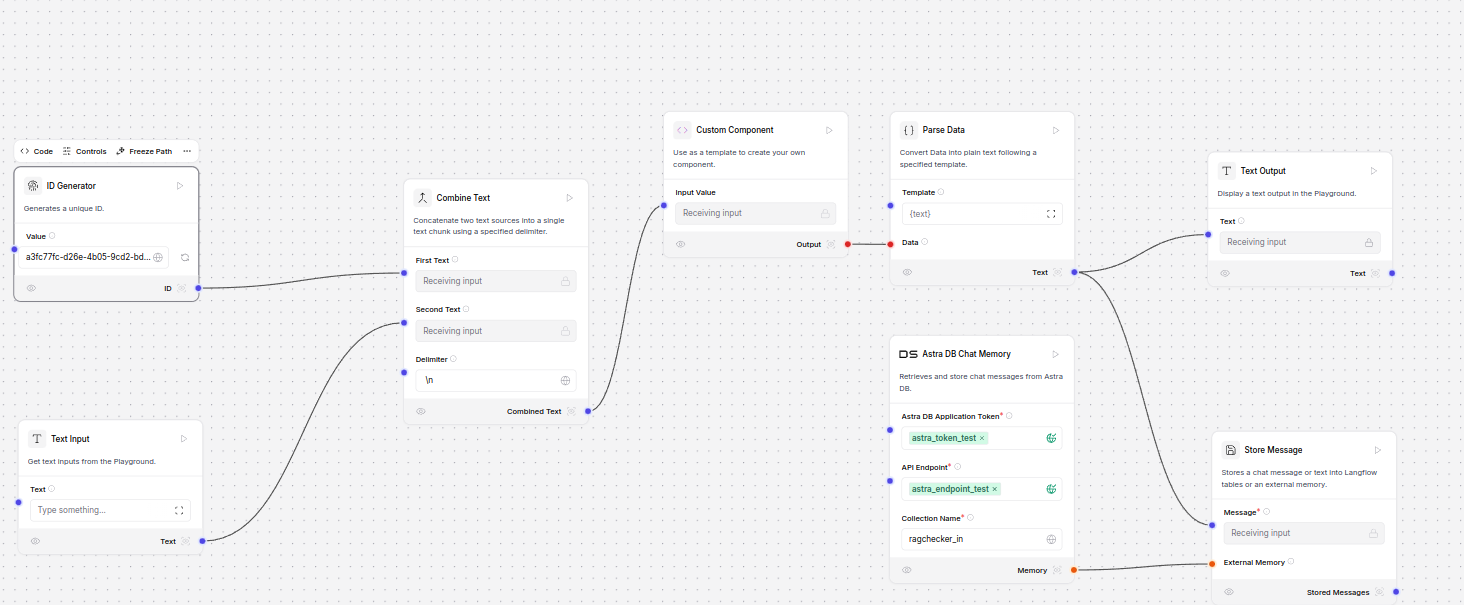 Langflow submodule logic generic to any LLM choice
Langflow submodule logic generic to any LLM choice
This framework enables us to iterate over different configurations, analyze the impact of changes to components such as vector store, embedding model, and LLM, and ultimately refine our applications for greater semantic accuracy. Beyond that, the dynamic capabilities of Langflow and the decoupled nature of the components allow the framework to rapidly absorb any changes necessary in the fast-moving world of AI and RAG applications.
If you haven’t already done so, go check out what you can do with Langflow in your own environment!



