
Today, most user customization is done via batch-processing data systems that take hours or days to run. These systems adjust system behavior for classes of customers—e.g., those interested in purchasing fitness products from a retail website.
But what if you could adjust system behavior for specific individuals? And what if you could do this on the fly, in real time?
The good news is that this is achievable in the age of AI. You simply need to shift your perspective on ML/AI systems. Instead of bringing your data to AI, you need to bring AI to your data.
Here, we’ll explore what this means and how to move your current batch-based data architecture to a real-time, AI-first architecture.
The shortcomings of current AI systems
Most AI systems, whether traditional or generative, are driven by batch processing. This is the “bringing data to your model” approach, in which data engineers collect new data and periodically retrain the underlying ML or AI model.
While cost-effective, this approach constrains AI systems in numerous ways:
It limits them to historical analysis. An ML e-commerce system can become very good at predicting seasonal volume. However, it can fail to pick up on unforeseen changes in the market, such as an unexpected supply chain issue or a new trend on social media.
It makes them unsuited to capturing real-time insights. ML/AI systems tend to use sparse data to keep data consumption to a bare minimum. This keeps data processing and transfer costs reasonable, but apturing real-time insights in these systems involves sending them through the same data migration and transformation process as historical data, which quickly becomes expensive.
In addition, these tools work too slowly to capture real-time insights. Most only run hourly or even daily (again, to keep costs low). By the time the data’s processed, it’s lost its relevance.
It results in siloed data and tools. AI practitioners often end up working independently and with different goals. This makes it difficult for teams to take dependencies on one another’s work. There are no data contracts, which means models can change unpredictably. This results in lost efficiencies that could otherwise be gained through cross-team collaboration.
What is real-time AI?
These batch-processing systems are based on bringing data to your AI. Real-time AI, by contrast, brings AI to your data, enabling you to direct users’ actions at the time they will have the most considerable impact.
Real-time AI is designed for speed and scale, enabling the delivery of the right data on the right infrastructure at the right time. Because it’s flexible and responsive, it can narrow in on specific users’ needs in the moment based on their behavior, rather than simply making decisions for user cohorts.
Many companies have successfully implemented real-time AI systems. TikTok built its Monolith real-time video recommendation system, for example, to tackle the exact problems discussed here. Monolith combines TikTok’s previous batch training stage for its TensorFlow training loops with an online component that consumes data on the fly and constantly updates a training parameter server.
How to implement real-time AI
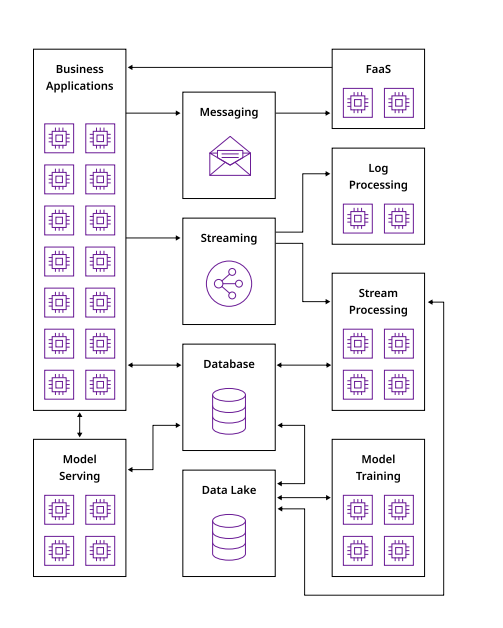
This shift doesn’t happen overnight. It requires making changes to your existing MLOps workflows to ingest, process, and act on data as it arrives. This requires making changes to your data architecture in three key areas:
-
Data management
-
Model serving
-
Model monitoring
Let’s look at each of these.
Data management
The first order of business is to store and transfer real-time data as it comes in. This can be done by creating an ML fact store, which stores data about specific entities as a moment in time. It’s best to store these in a NoSQL database, as the shape of the data you capture will change over time.
Once stored, facts can be transmitted for either batch or real-time processing. Real-time processing messages are sent through a stream processing engine, such as Spark Structured Streaming or Flink.
Finally, you create features from this data to drive training and store them in a feature repository, developing low-latency queries to serve these features to your training and inference layer. Feature repositories should also be implemented in a NoSQL database for best query performance, which we’ll discuss more below. (We have a guide on how to do this using Astra DB, our NoSQL database built on Apache Cassandra®.)
At this stage, you decide which features to develop, along with other system attributes, such as the ideal mix of on-disk versus in-memory storage for durability and performance.
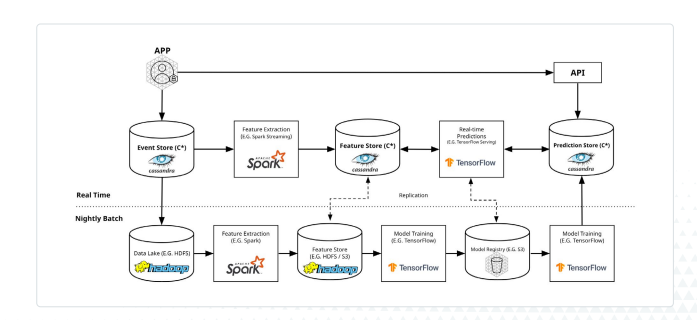
Model serving
Also known as inference serving or prediction serving, model serving can occur in one of several ways:
-
Online, in near real-time
-
Streaming in near real-time via an event-processing pipeline
-
Embedded in a device or on an edge compute node
-
Offline for bulk data scoring
This is where using a NoSQL database for feature serving pays off. Online inference operations have extremely tight SLAs: they need to return to the user in ~100ms so as not to drag down the performance of the system.
Many model serving systems can’t pull data this quickly from feature repositories. By contrast, NoSQL systems excel at such fast queries, making them ideal for this situation.
Model serving—particularly for AI systems such as large language models (LLMs)—requires expensive GPUs to calculate and serve. Incorporating a caching layer here can significantly reduce the costs of enabling real-time training and inference.
Model monitoring
Real-time AI isn’t just a matter of “run it and forget it.” Your models can become inaccurate over time due to several factors:
-
Data drift - The distribution of your training data differs from that of your real-time data
-
Training-server skew - Your model training code and real-time feature serving code diverge
-
Concept drift - The relationship between your model’s input and output data changes, rendering the patterns inaccurate
Real-time processing is more susceptible to these problems. Particularly, it’s more sensitive to real-world events that render your model’s assumptions invalid.
To prevent this, you need to put in place rigorous monitoring that can detect drift and alert the engineering team that there’s an issue requiring triage. This system should contain both real-time and batch components so you can fully detect drift in distributions, code, and relationships.
Once again, a NoSQL database serves here as a high-performance solution for storing and querying the large volumes of data required. This includes predictions served, features used, and the final result.
Building an architecture to support real-time AI
There are many additional details to iron out in this architecture. A few include:
-
How to model and supply your data
-
Which tools to adopt to enable data scientists and ML/AI application developers to collaborate on solutions
We go into more detail in our white paper on standing up a real-time AI architecture. There, we dive into tooling, shaping your data, and other architectural components such as stream processing, data lakes, and log processing.
Supporting real-time AI requires a robust NoSQL database that delivers fast query times for data management, model serving, and model monitoring operations. Astra DB is a low-latency NoSQL and vector database designed to support AI app creation and development. It scales to petabytes of data, delivering world-class performance at a fraction of the cost of other solutions. Sign up for a free account today and discover the difference for yourself.



