The power of modern large language models (LLMs) is well known at this point, with services like ChatGPT and Gemini becoming almost ubiquitous in modern computing. But one topic that receives less attention is leveraging data that was not incorporated into those LLMs in the first place—this data could be new information, internal company data, or context that is important for the subsequent queries that will be sent to the LLM.
Providing supplemental context when querying the data is a way to incorporate this information, but that begs the immediate question of where the context itself comes from. Glean provides a unified, powerful framework for indexing and searching company data, ranging from internal and external documentation to GitHub commits to JIRA tickets and associated information. This significantly increases the potential power of a retrieval-augmented generation (RAG) framework, because it enables the seamless incorporation of a wide variety of data sources that would otherwise be unavailable to a typical retrieval tool.
Here, we’ll walk you through the process of setting up a flow using the powerful low-code Langflow framework, which pulls data from the Glean Search API, and enables the construction of an easy-to-use RAG pipeline to answer questions based on your data that would not typically be available to LLMs, all through an easy-to-use interface.
Background
For this post, we’re leveraging three key technologies:
- Astra DB - Astra DB is a serverless NoSQL database that powers modern AI applications with near-zero latency and includes modern features such as vector search, with client libraries and integrations across a whole host of cutting edge AI frameworks.
- Glean - Glean is a work AI platform that securely connects to a vast array of data sources and enables developers to build AI applications on top of the data.
- Langflow - Langflow is a low-code interface and platform for building powerful AI applications that integrate reusable “components” of simple Python code to create flows.
As a preliminary step, we have indexed internal data sources into Glean using the Indexing API. With that in place, we can now query the Search API to pull data in a structured, easy-to-parse format. Making an API call to the Search API is straightforward, following a format like this:
curl -X POST "{glean_api_url}/search" \
-H "Authorization: Bearer {glean_access_token}" \
-H "X-Scio-ActAs: {act_as}" \
-H "Content-Type: application/json" \
-d '{
"query": "{query}",
"pageSize": {page_size},
"requestOptions": {request_options}
}'The primary parameter is the query, and is provided along with optional page size and request options. You must provide an appropriate Glean Access Token, which scopes the data that is retrievable in the API call and ensures that end users don’t get access to information they otherwise shouldn’t.
For purposes of this post, we’ll gloss over this step in favor of the aforementioned Glean documentation and focus on the integration portion, using Langflow to build an AI pipeline leveraging this data.
The Langflow Glean Component
One major aspect of the integration between Astra DB and Glean is the Langflow Glean Component, which we call Glean Search API. This component provides a Langchain Tool and a data output, which represents the result of calling the Glean Search API with a given query and parameters. Below is a screenshot of how the component looks in the Langflow UI.
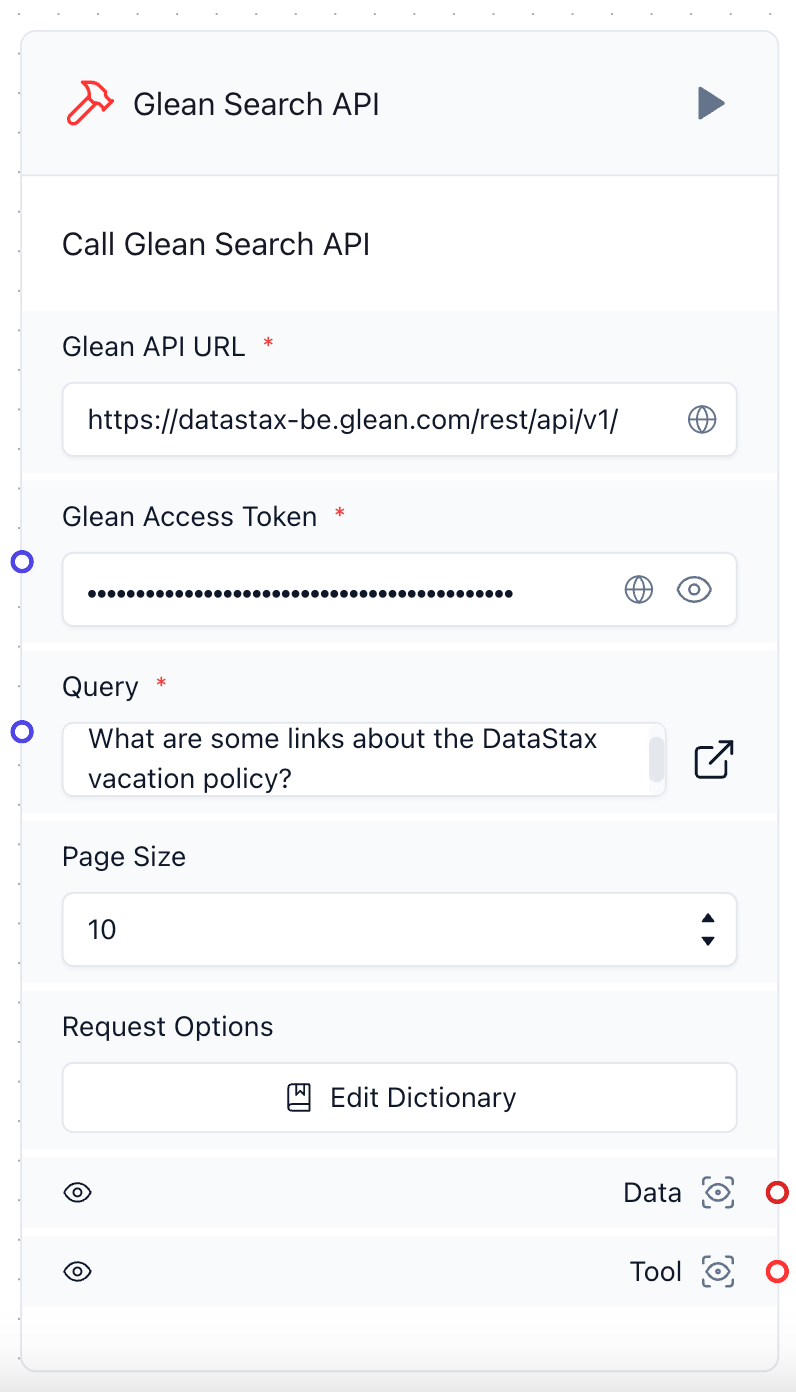
Note the parameters we provide:
- Our Glean API URL, which for this example is our DataStax Glean instance
- An access token for retrieval of the data
- The query itself
- Optional parameters for page size and other request options that filter and refine retrieval results
When we execute the component, we receive back search results related to that query and the metadata associated with each, which you can view by clicking the Data output of the component.
Building a Glean search agent in Langflow
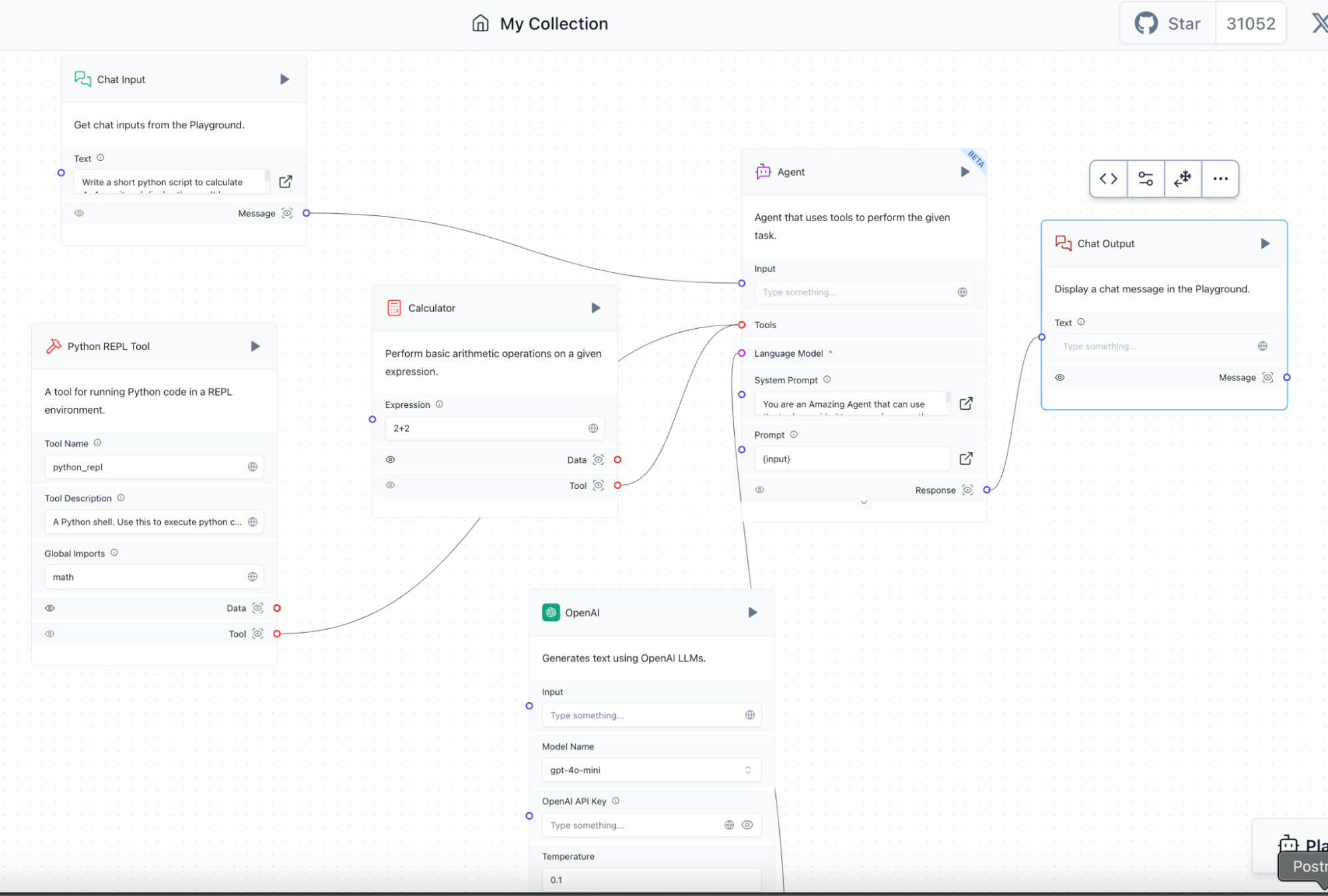
Now that we’ve seen the component in action, we can turn our attention to creating an interesting flow that incorporates the results. Langflow provides a number of starter templates when you create a New Project. To create our Glean Search Agent, we’re going to start with the Simple Agent template, and make some minor modifications to incorporate Glean as the data source. When you create a New Project and choose Simple Agent, you are presented with a flow that includes two Langchain tools - a calculator and a Python code generator - that are inputs to the Agent component. The preliminary flow is shown in the diagram below.
Now we replace the Python REPL Tool and Calculator Tool with the single Glean Search API Component. Make sure to connect the Message output of the Chat Input Component to the Query input of the Glean Search API Component, as well as the Tool output of the Glean Search API Component to the Tool input of the Agent component. Make sure to also fill in both your OpenAI API Key, and your Glean Access Token. The result of replacing the specified components and making the appropriate connections between inputs and outputs is illustrated in the diagram below.
A note about LLMs: This flow takes context provided by Glean and passes it to the LLM of choice, in this case OpenAI’s gpt-4o-mini model. Because potentially sensitive or internal data can be indexed by Glean, it is important to make sure that when online LLMs are used for processing, care is taken to ensure that any data accessible is safe to provide to the provider of choice. Choosing a local or privacy focused LLM, or better curating the data indexed into Glean, can be ways to address this concern.
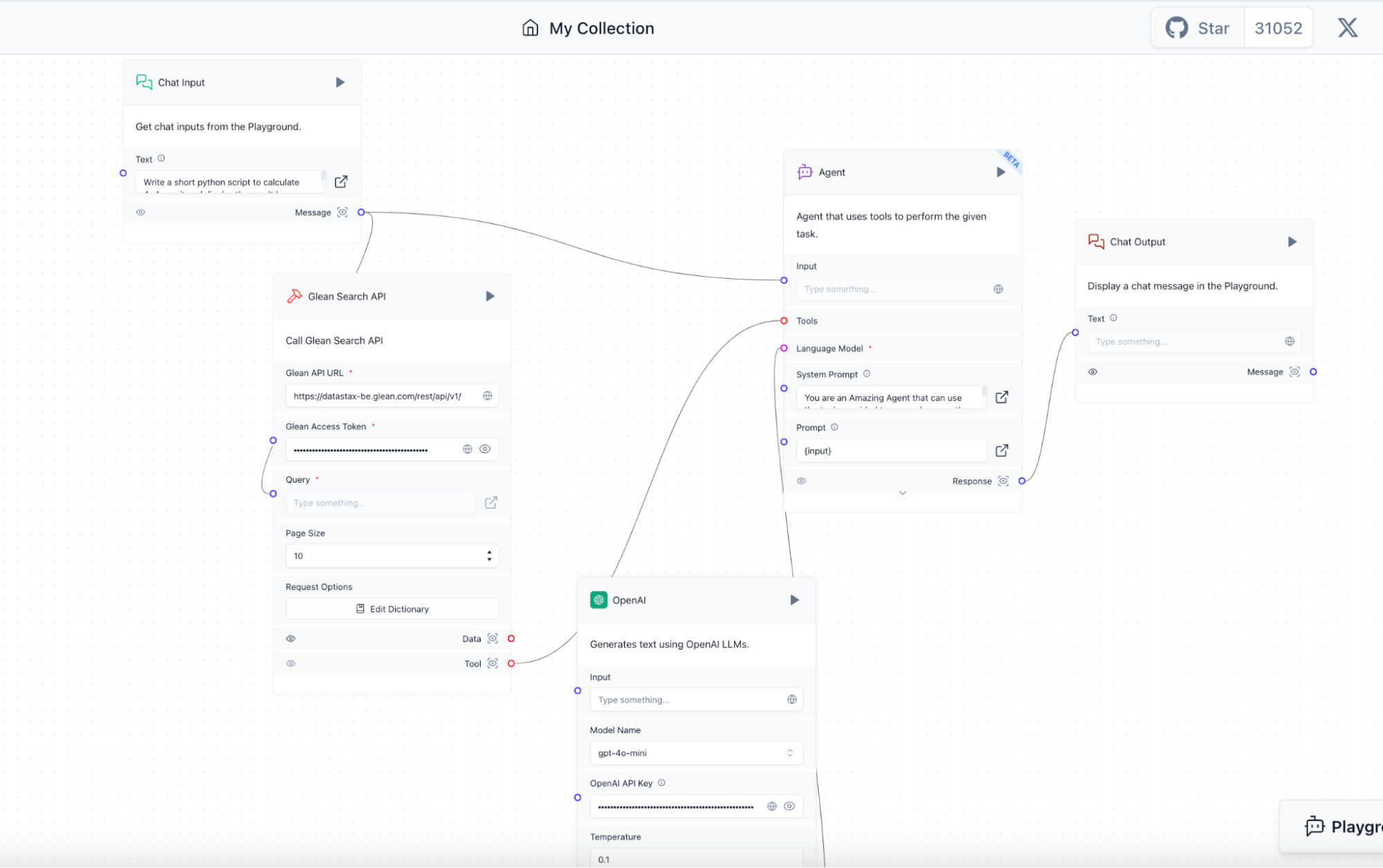
Next, we click the “Playground” button to interact with our Glean data as if it’s a company-focused internal chat bot! Here I ask for some information about the DataStax vacation policy, which pulls in appropriate intranet links that are accessible to employees.
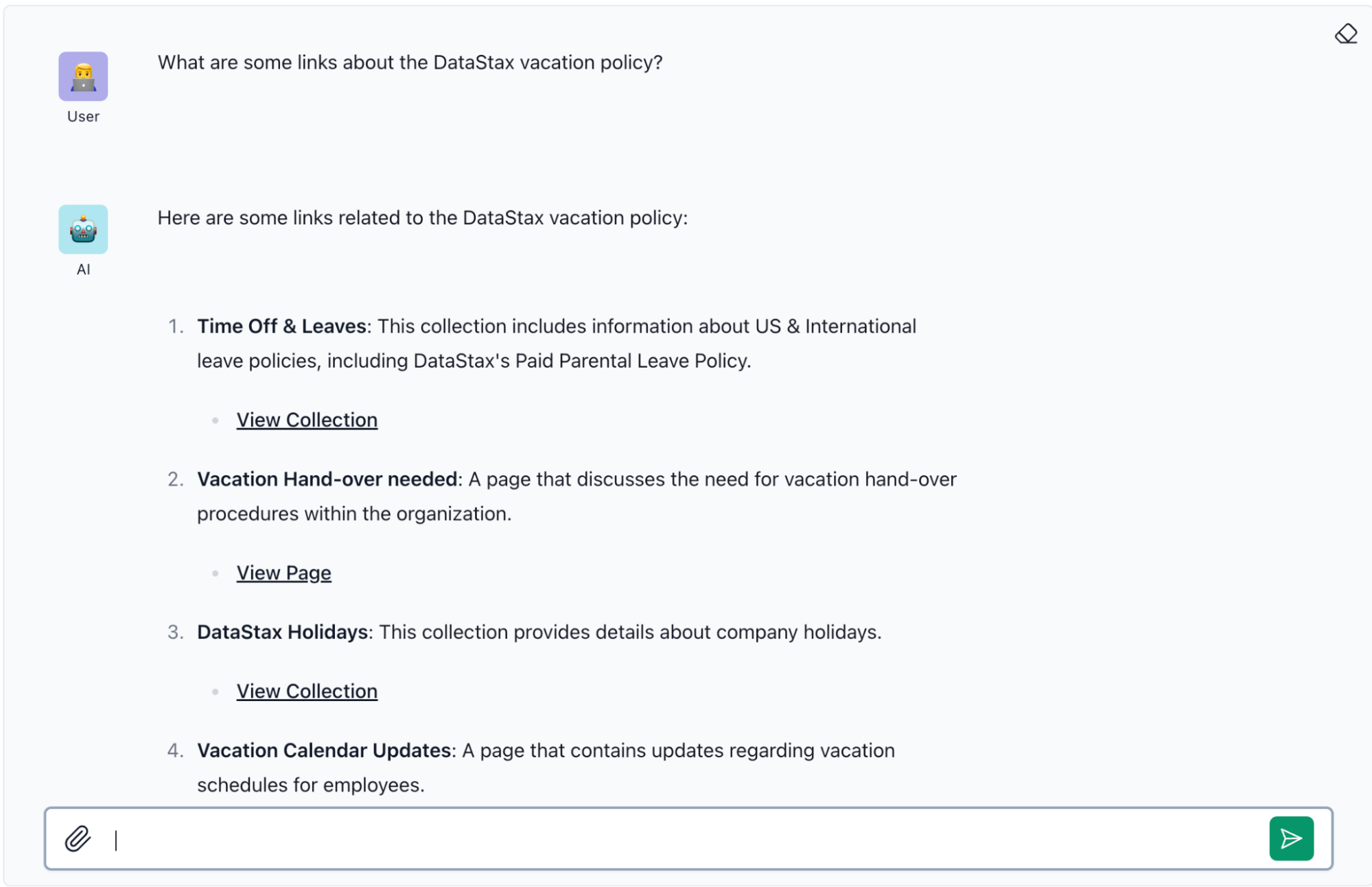
While we created this powerful Langflow flow with just a few clicks in the UI, under the hood there is a pretty interesting AI pipeline being executed. From sending a message in the Playground to retrieving a response, a high-level explanation of the steps is as follows:
- The Playground message is sent to the Glean Search API component as the search query, with the top 10 results retrieved.
- A LangChain Tool is created, which instructs our Agent to query Glean in order to process a response to the given query.
- OpenAI embeddings are generated by the agent for the given query to match to the relevant results.
- The output from the agent is provided to the playground as a chat message from the AI.
There are several ways to refine the agent’s outputs and final response, such as using a system prompt to guide how the query is handled. Langflow offers a simple, low-code interface for constructing these flows easily, while also allowing advanced customization with full access to the underlying Python code.
We’ve just scratched the surface of what’s possible with Glean, Astra DB and Langflow, yet we still implemented an agent that can be of immediate use for both DataStax employees and other organizations, big and small.
Wrapping up
In this blog, we demonstrated how to build an AI workflow using Glean, Astra DB and the Langflow user interface. With a few clicks, we created an interactive agent that queries internal data beyond the scope of traditional RAG workflows. The flexibility of these platforms extends far beyond what we’ve shown, but we hope this highlights their accessibility and inspires ideas for modern AI applications.
Try the Glean Langflow Component for yourself: register for Astra DB and Glean today.
For more, check out the replay of our recent livestream with Glean, “Deploy Enterprise-Grade Agentic RAG with Glean and DataStax.”



