What is an LLM agent?
An LLM agent is any system that leverages an LLM using natural language to complete complex business tasks. They combine calls to one or more LLMs together with calls to other systems and tools to answer complex questions, even engaging in multi-step chains of reasoning.
For example, you might create an LLM agent that can address an employee’s specific question about their benefits. This can require integrating multiple systems together, such as one or more LLMs, employee data from your internal human resource management systems, external insurance providers, and documentation and knowledge bases pertaining to employee benefits.
LLM agents can be used for a number of tasks, including answering questions, summarizing information, analyzing sentiment, extracting data, and more.
Components of an LLM agent architecture
An LLM agent can consist of a number of parts. Here's one way to conceptualize the various components involved:
LLM: LLMs remain the most important element in an agent architecture, serving as the brain of your GenAI app. They provide a general-purpose engine for human language interpretation and generation, along with a common knowledge base trained on massive amounts of data. In an agent architecture, these can be either externally hosted LLM services or your own internally hosted models.
Retriever: Retrievers are components that access data stores containing supplementary information that can be queried and included in calls to the LLM. They serve a critical role in providing domain-specific data tailored to your use cases. Retrievers are key to implementing retrieval-augmented generation (RAG), the most reliable known technique for improving LLM response quality.
Memory. Memory provides access to earlier steps in a chain of reasoning (short-term memory) or to conversations from previous sessions (long-term memory). This requires stating state at various checkpoints and ensuring you add this memory as context to feature discussions.
Tools. A tool is any resource that agents use to connect to external environments to help with certain tasks or even to perform actions on a user's behalf. This can be a stock ticker or weather API, an API that decides the best LLM model to route a particular request to, or a call to a system that performs actions such as password reset requests or employee benefits changes.
Complex approaches to tools use an LLM’s analytical and reasoning capabilities to make tooling decisions. For example, the Toolformer approach uses a model trained in deciding what APIs to call to determine the next step an agent will take.
Planning. The planning component breaks down complicated tasks into simpler tasks and forms an execution plan. It decides which LLMs and tools to call and in what order. It may also identify subtasks that can run in parallel or include human-in-the-loop mechanisms to solicit expert human insight for highly sensitive tasks.
Three LLM agent architectures
Not all agent architectures will need to use each of these components. Working with customers on countless GenAI app projects, we've identified three basic patterns:
- Pattern 1: Single LLM call
- Pattern 2: LMM + retriever
- Pattern 3: LLM + tools + memory + retriever
Let’s look at each of these patterns in detail.
Pattern 1: Single LLM call
The simplest pattern is calling the LLM directly. Yes, I know — I said at the beginning that this wasn't the most interesting or, in many cases, reliable scenario. However, there are some use cases not requiring domain-specialized knowledge in which a simple LLM call will get the job done.
A great example is performing sentiment analysis on a stream. In this case, you extract text that comes from a source—such as a social media service—and use an LLM to determine if someone's remark about your company or product is positive or negative.
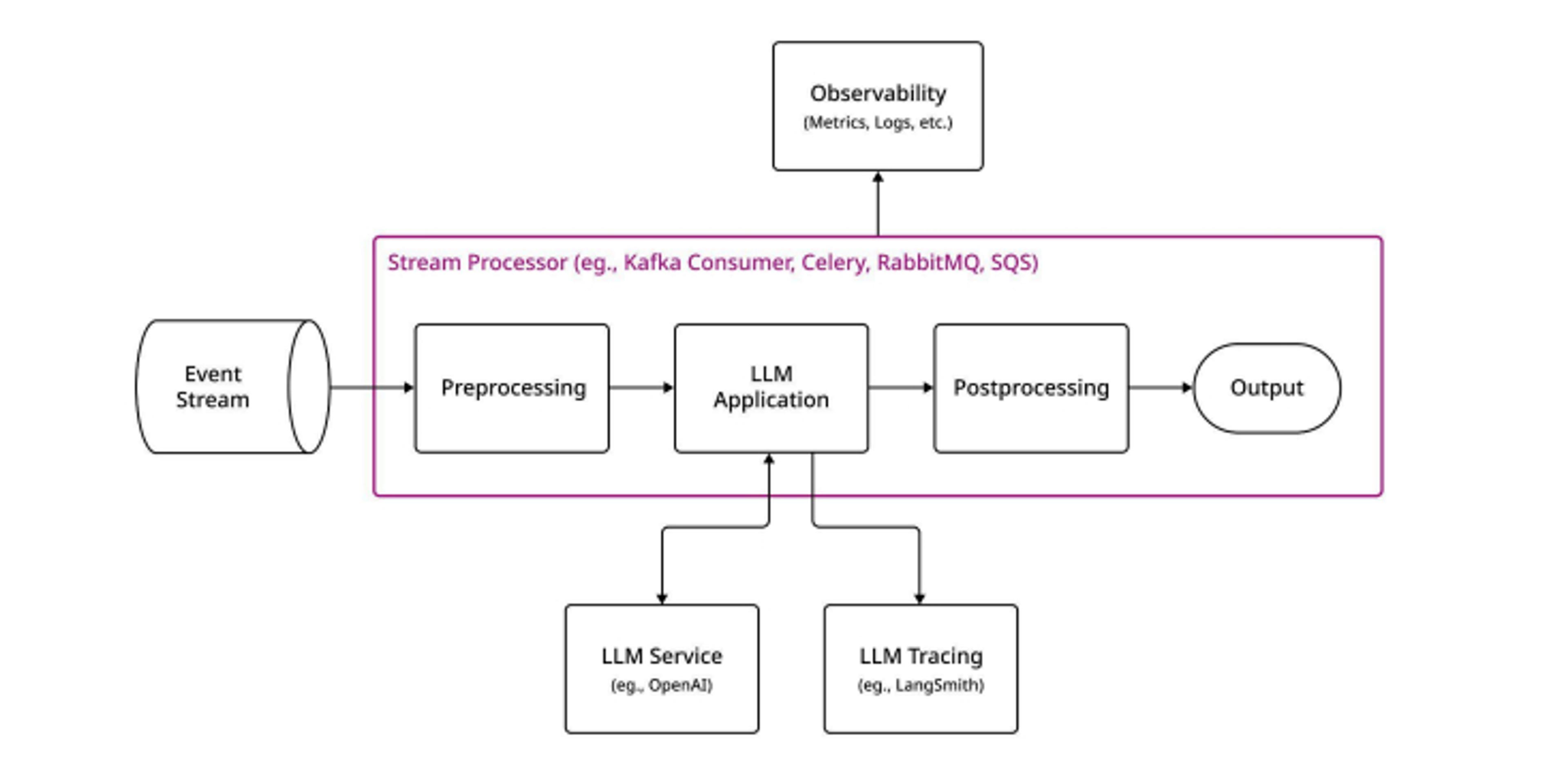
These use cases have a couple of hallmarks. First, they’re generally back-end processes not directly called by a user —for example, a Kafka stream processor or a Celery/RabbitMQ message processor. Second, they don't require any specialized knowledge beyond the LLM’s own base knowledge and native language processing capabilities. In this case, for example, LLMs are capable on their own of detecting positive or negative sentiment.
Pattern 2: LLM + retriever
Our second pattern is the most common: adding one or more external knowledge sources to your LLM calls. This is the RAG scenario, in which we query a knowledge store, such as a vector database, to retrieve external context that will enable the LLM to provide more relevant answers. The most common use case here is a customer service chatbot with access to a database of product documentation and past support cases.
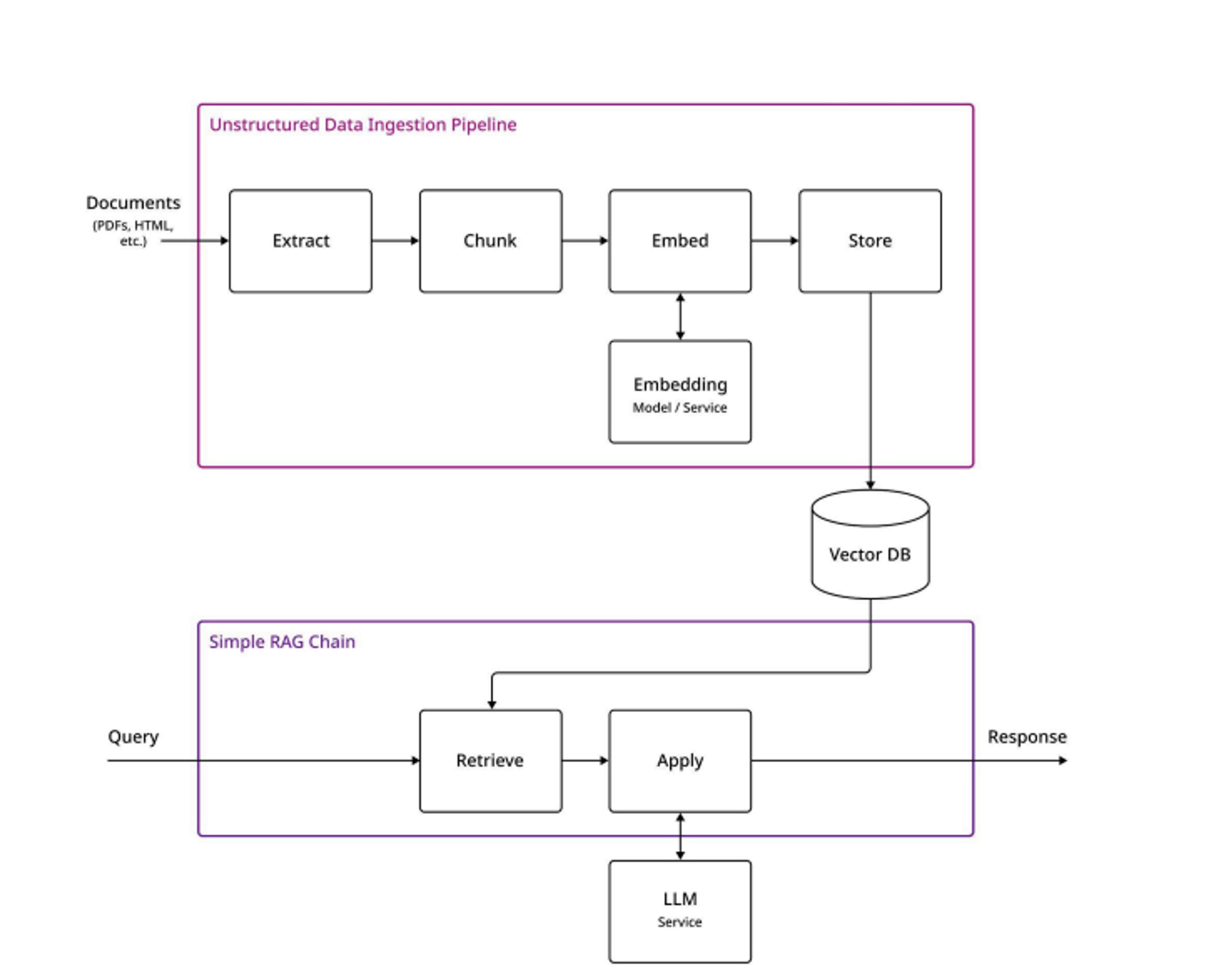
This architecture consists of two distinct components. The first is the ingestion pipeline, which ingests unstructured documents, chunks them, grabs metadata embeds, and stores them in a database. Documents are typically converted to either vector or graph format and then accessed either via vector similarity search or graph traversal.
The second is the RAG agent chain. Here, instead of calling the LLM immediately, we query our external data source first, gather and filter any relevant context, and include it in the prompt we send to the LLM.
Pattern 3: LLM + tools + memory + retriever
Finally, our third architecture combines all of the elements of an LLM agent to enable high-quality, contextual responses, along with historical recognition. This can be an autonomous customer service chatbot that recognizes customers, tailors its responses to their past support history, and even performs actions (such as generating a password reset request) on their behalf.
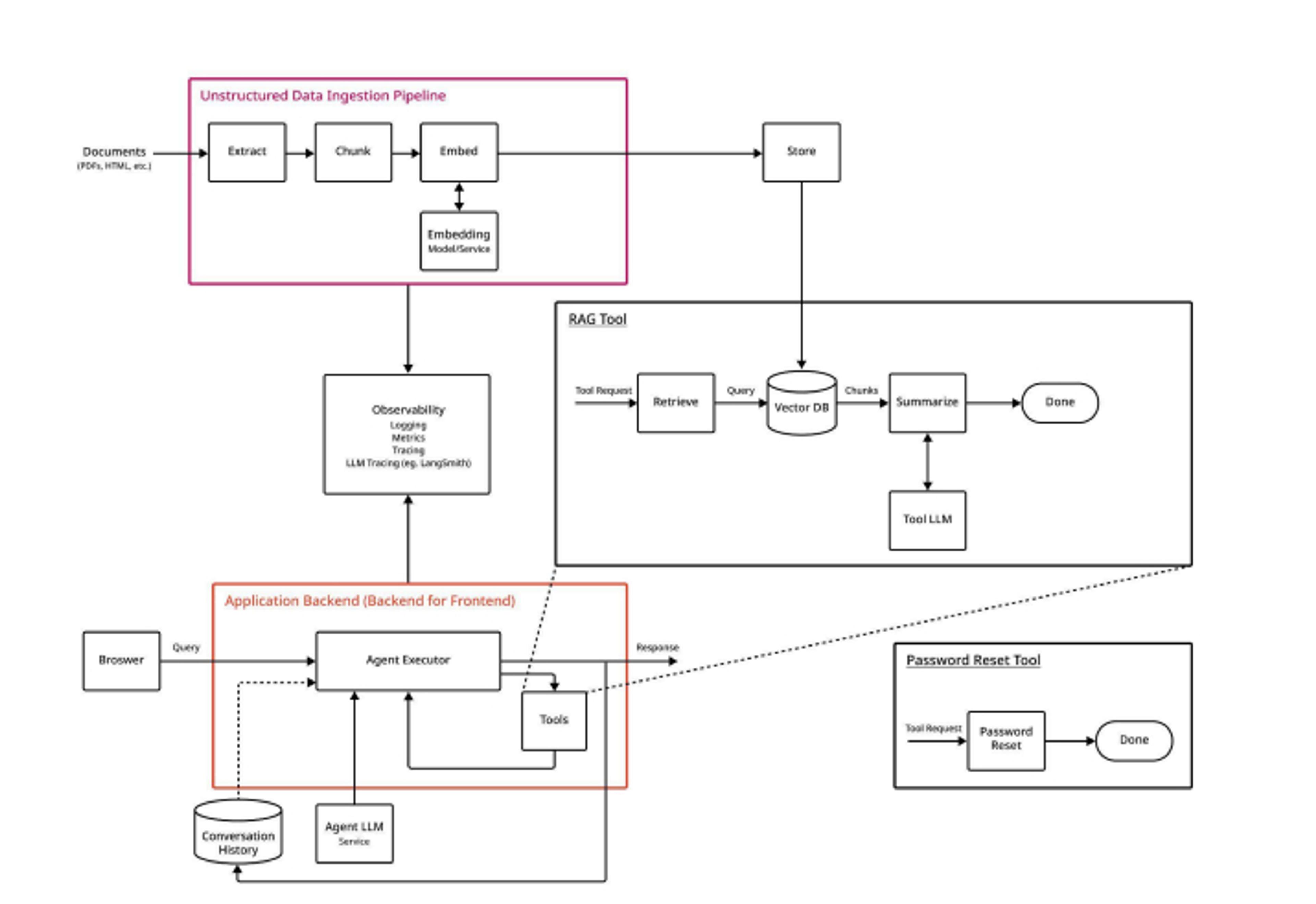
The key to this architecture lies in the agent application backend. Instead of a hardcoded set of rules following a determined pattern, the agent is a dynamic component that uses an LLM to decompose complex tasks into numerous steps. The LLM determines not only which action should be taken but which tools should be called to carry them out.
This architecture allows the agent to respond to more complex requests. It may, for example:
- Break a single task into multiple subtasks, parceling these subtasks out to other LLMs or agents that specialize in specific topics
- Run unrelated tasks in parallel to achieve the lowest possible response latency
- Employ an evaluator that verifies the veracity of an LLM’s response and refines it to achieve more accurate output
Other considerations in LLM agent architecture
Whichever architecture you employ, there are a few guidelines you should follow when creating AI agents:
- Use RAG first, fine-tune later. Fine-tuning is an approach to improving AI accuracy that re-trains all or a subset of the training parameters in an LLM. While it has some advantages (particularly with making improvements to style and tone), it’s not the best or most efficient way to teach an LLM new knowledge. Additionally, RAG generally outperforms fine-tuning in terms of improving accuracy. Focus on RAG first and then use fine-tuning only if you need to make specific, tailored improvements.
- Use an orchestration tool. There’s nothing stopping you from coding LLM agents from scratch. However, AI platforms give you a leg up by providing 90% of the functionality you’ll need for agents - including retrievers, document parsers, memory, and tools integration - as out-of-the-box components. Using an AI platform like DataStax, powered by LangChain and Astra DB, can cut the time it takes to take an idea from prototype to production. The open-source LangChain provides a framework for building out production-ready AI apps quickly using chains of reusable components. For example, LangChain’s LangGraph enables building a dynamic agent that can create execution plans and call tools. Meanwhile, Astra DB provides serverless, scalable vector database storage at petabyte scale.
- Use observability and evaluation tools. Continuous monitoring provides insights into not only how your application is performing but also how accurately it’s behaving. Use tools like OpenTelemetry to track metrics such as request latency, average conversation length, and response reliability scores. Tools such as LangSmith can make this easier to implement.
Learn more
The complexity of AI agents is a sliding scale - and it’s one you can adjust as you become more comfortable with the technology. You can start with simple back-end calls to an LLM and gradually grow your way into customer-facing systems that remember past conversations and perform actions on a user’s behalf.
LLM agents really shine when we use AI itself to make decisions on our behalf at scale. Built well, LLM agents can create their own complex query plans, choosing the best tools and execution strategies dynamically based on context.
There’s a lot more to building reliable LLM agent architectures. For more details to help get you started, download our white paper on understanding and building complex LLM agent systems.