
Over the past year, DataStax has partnered with NVIDIA to adopt and adapt the NVIDIA NeMo microservices, part of NVIDIA AI Enterprise, to add generative AI, retrieval-augmented generation (RAG), and hybrid search functionality for Astra DB, DataStax Hyper-Converged Database, and the DataStax AI Platform, powered by NVIDIA AI, which we launched last October. This includes the recent launch of DataStax Astra DB Hybrid Search, which improves semantic, lexical, and vector search relevance by 45% using NVIDIA NeMo Retriever microservices. Looking for the punchline? See our results: 19x better performance in throughput, a significant reduction in costs, and improved latency, with sub-12ms latency on NVIDIA H100 GPUs. These results are crucial for scalable RAG and hybrid search in production.
NVIDIA NeMo microservices are now integrated into Langflow, enabling devs to build agentic AI with drag-and-drop simplicity. This supports continuous optimization through data flywheels—feedback loops that refine models using real-world data. Developers can now fine-tune AI agents directly on enterprise data without moving it elsewhere.
This post explains how we leveraged NeMo microservices to build our data and AI platform, which helped customers like Wikimedia Deutschland launch their AI Knowledge Project 10x faster with DataStax.
How we started: Vectorize. Embed. Retrieve.
With the growing popularity of GenAI, our customers wanted an easy way to build and run AI applications where they kept valuable enterprise data - the industry term is “data gravity.” The first step was to ensure we could support the data format required for AI applications - namely, the ability to store vectorized data formats. In June 2023, we introduced vector search capabilities to Astra DB, enabling developers to leverage vector embeddings for AI applications. A year later, DataStax was recognized as a leader in the Forrester Wave for Vector Databases— a distinction we’re quite proud of.
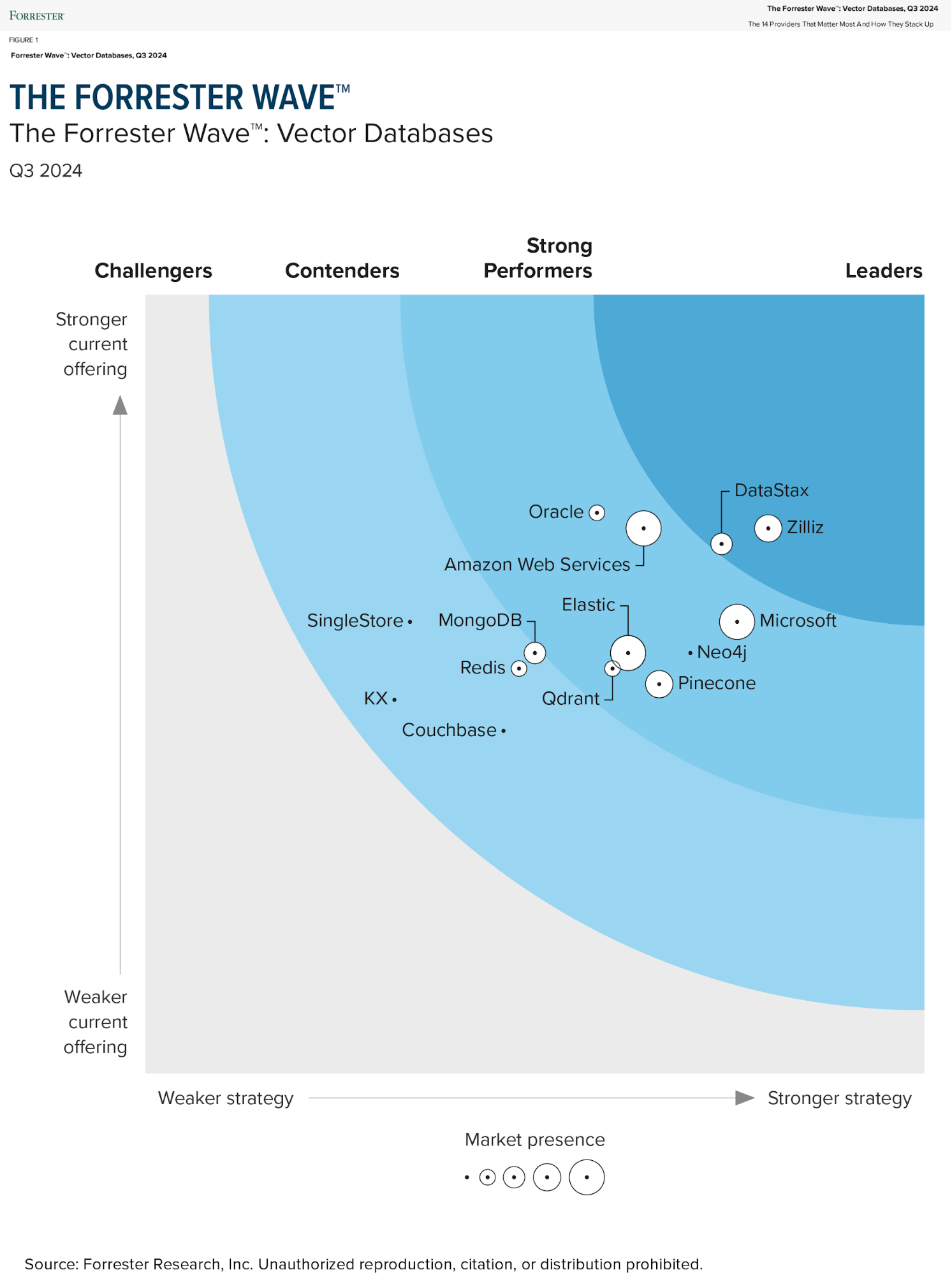
We decided to explore whether NVIDIA NeMo microservices could be used to expand Astra DB’s GenAI capabilities.NVIDIA’s open-source AI tools, models, and frameworks caught our attention as a way to speed up product development at DataStax. With urgent customer needs and a fast-moving market, choosing NVIDIA was a no-brainer. NVIDIA has been developing many of the open source frameworks, models, and runtimes that power the AI boom so we were curious whether the new Enterprise AI solutions from NVIDIA could be used to compress our product development sprints and help DataStax get to market faster. Our customers needed solutions now, and the market was moving fast. The choice was simple.
Based on initial benchmarks, we concluded that a native embedding service provided the requisite high throughput, low latency, and low total cost of ownership (TCO) options we needed. NeMo Retriever was 17x faster and 80% cheaper than other solutions. We ran the benchmarks on a single NVIDIA A100 Tensor Core GPU, which demonstrated increased performance from ~181 ops/second to almost 400 ops/sec. Tuning NVIDIA TensorRT software with a tokenization/preprocessing model improved performance by another 25%. We then switched to the NVIDIA H100 80GB Tensor Core GPU (a single a3-highgpu-8g instance running on Google Cloud), which resulted in throughput doubling to 800+ ops/sec. We also looked at configurations that lowered the latency, and found that it’s possible to achieve ~365 ops/sec at a ~11.9 millisecond average embedding + indexing time, which is 19x faster than popular cloud embedding models + vector databases.
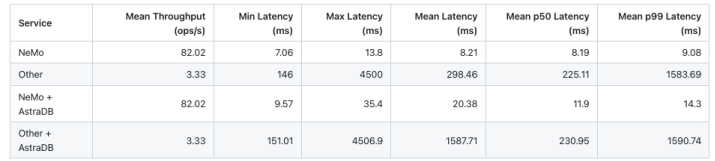
The Astra DB vector database uses DiskANN to process 4,000 inserts per second and make them immediately searchable. While this keeps the data fresh, the tradeoff is reduced efficiency. We’re working with NVIDIA to accelerate vector search algorithms by integrating NVIDIA cuVS to improve efficiency and maintain data freshness. When combined with NeMo Retriever, Astra DB, DataStax Enterprise (our on-premises solution) and DataStax HCD, this provides a fast vector database RAG solution that’s built on a scalable NoSQL database that can run on any storage medium.
We started by integrating NeMo Retriever embedding and reranking models as the RAG solution for deploying AI models with faster embeddings and indexing.
We chose NeMo Retriever because it provides two key features:
- Embedding models to transform diverse data—such as text, images, charts, and video—into numerical vectors while capturing their meaning and nuance. Embedding models are fast and computationally less expensive than traditional LLMs.
- Reranking models that ingest data and a query, score the data according to its relevance to the query, and trim results to include only the most relevant responses. Such models offer significant accuracy improvements while being computationally complex and slower than embedding models.
In May 2024, we launched Astra Vectorize, which enabled embedding generation at the database tier for simplified and cost-effective integration of unstructured data into GenAI workflows. Customers had the option of using any embedding service they wanted, and we also offered NeMo Retriever as the built-in solution. This is also when we announced the launch of DataStax Hyper Converged Data (HCD) Platform, which brings OpenSearch and Apache Pulsar, enabling customers to add GenAI and vector search capabilities to their self-managed enterprise data workloads.
By July 2024, we were ready to open the service to our cloud and DBaaS customers - NVIDIA NeMo microservices would be pre-installed as the default embedding service in Astra DB.

We used NVIDIA NeMo microservices as building blocks in early development because we could swap out new models quickly and easily as better retriever and reranking SLMs were released. The models were provided as production-ready NVIDIA NIM for Docker and were easy to deploy, and optimized for performance. We pip installed each module manually onto our Astra DB instance hosted on Amazon AWS, but the latest GA version expands operational controls with Docker Compose and HELM charts to automate and control fleet deployment (this will be important further down in this post as we expand from DBaaS to on-prem software).
Langflow and the DataStax AI Platform
In April 2024, we acquired Langflow, a low-code tool for developers that makes it easier to build AI applications. Langflow enables developers and data scientists to build AI agents and workflows using a drag-and-drop interface, simplifying the process of building AI applications with models.
 In this example, Langflow enables developers to create a “flow,” which organizes components such as gateway URLs, embedding providers, RecursiveCharacterTextSplitter, and Astra DB.
In this example, Langflow enables developers to create a “flow,” which organizes components such as gateway URLs, embedding providers, RecursiveCharacterTextSplitter, and Astra DB.
By October 2024, our AI innovations culminated in the launch of the DataStax AI Platform, built with NVIDIA AI. The new platform integrates DataStax’s existing database technology, including Astra DB for cloud native and Hyper-Converged Database (HCD) for self-managed deployments. It also includes Langflow to build out agentic AI workflows, and NeMo microservices to accelerate and improve the organization’s ability to rapidly build and deploy models.
Hybrid Search and beyond
The next step in the evolution of data and GenAI is to use advanced models to improve search accuracy. In March 2025, we launched Astra DB Hybrid Search, which combines vector search (for semantic understanding) and lexical search (for exact keyword matching) to improve search relevance by 45%. Blending these signals effectively requires intelligent ranking—and that’s where the NeMo Retriever reranking microservice comes in.
Astra DB performs hybrid retrieval, combining lexical search using BM25 and vector search powered by Apache Cassandra®. The top results are passed through the NeMo Retriever reranking microservice, which reorders them based on fine-tuned LLM models, significantly improving relevance. Astra DB hosts the NeMo Retriever reranking service for you. Your data stays within Astra DB and reranking is automatically enabled when you need it. You don’t have to configure your reranker; you can use it out-of-the-box via the Data API.
What are NVIDIA NeMo Microservices?
NVIDIA NeMo is an end-to-end platform for developing AI agents and GenAI applications. It includes microservices for customizing, evaluating models, RAG, guardrails, and data curation tools. It offers enterprises an easy, cost-effective, and fast way to adopt generative and agentic AI. Some of the specific NeMo microservices that are interesting to DataStax include:
- NeMo Retriever is a collection of GenAI microservices that provides leading information retrieval, reranking, and document extraction with high accuracy and maximum data privacy, enabling enterprises to generate business insights in real-time. NeMo Retriever includes models from NVIDIA, Meta, Mistral, and others, giving us flexibility to use the right combination of extraction, embedding, and reranking models. It also enables easy upgrades, which is important as models continue to develop, adding more languages, multi-modal inputs, and better accuracy.
- NeMo Customizer is a high-performance, scalable microservice that simplifies fine-tuning and alignment of LLMs for domain-specific use cases. We use NeMo Customizer to fine-tune NeMo Retriever microservices in combination with community or custom models to build scalable data extraction pipelines, document ingestion, and RAG applications, which can be connected to proprietary data wherever it resides.
- NeMo Evaluator provides assessment of GenAI models across academic and custom benchmarks on any cloud or data center.
- NeMo Guardrails implements robust safety and security measures in LLM-based applications, ensuring that the applications remain reliable and aligned with organizational policies and guidelines.
The unified architecture: Data fuels AI
At the heart of effective GenAI applications lies a fundamental truth: data serves as the essential fuel that powers both capabilities and adoption. The data flywheel we referenced earlier—that self-reinforcing feedback loop where data collected from interactions trains and refines AI models to generate better outcomes—requires a thoughtfully designed architecture to function effectively.
To build a platform that sustainably powers this data flywheel, we've structured our architecture into three distinct yet interconnected layers:
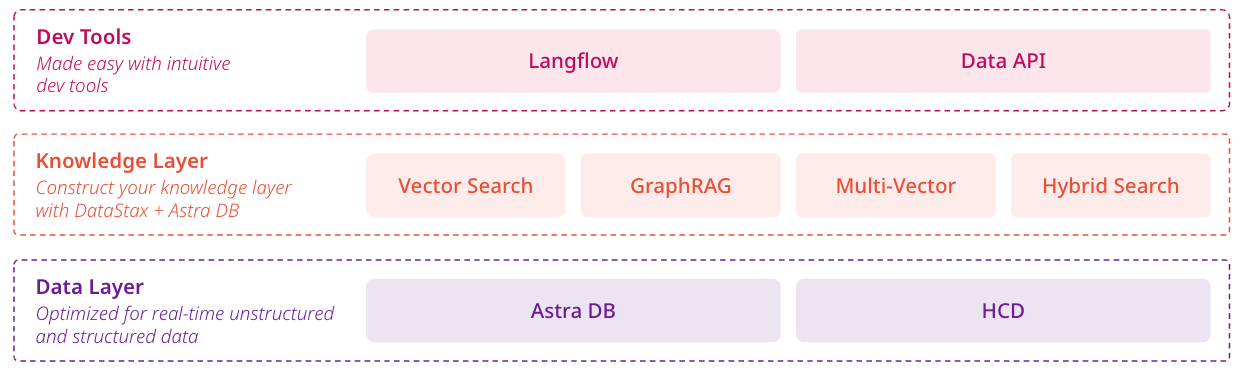
Data layer: The foundation
The data layer serves as the bedrock of our architecture, providing real-time storage and retrieval for both structured and unstructured data. This is where Astra DB and DataStax HCD excel, offering:
- High-performance vector storage with DiskANN, processing 4,000 inserts per second with immediate searchability
- Scalable NoSQL architecture that respects data gravity principles, allowing AI to operate where your data lives
- Seamless integration with enterprise data sources while maintaining security and governance
This layer ensures that the flywheel has access to fresh, relevant data at all times, creating the foundation upon which AI intelligence can be built.
Knowledge layer: The intelligence
The knowledge layer transforms raw data into actionable intelligence through AI-augmented processing. At the knowledge layer, we also introduce more advanced techniques that can help customers achieve higher levels of accuracy and throughput, such as graph RAG, low-latency vector search powered by JVector, sparse and dense embeddings, and Hybrid Search. This is where NVIDIA NeMo microservices provide their greatest value:
- NeMo Retriever for embedding generation and reranking, improving search relevance by 45% through hybrid capabilities
- NeMo Customizer and Evaluator for fine-tuning and assessing models on domain-specific data
- NeMo Guardrails for implementing robust safety measures while maintaining performance
This layer enhances the data flywheel by continuously improving the quality of AI responses based on previous interactions, creating a virtuous cycle where better results lead to more engagement, which produces more data for training.
Dev Tools: The accelerator
The top layer provides intuitive, developer-friendly tools that dramatically accelerate the journey from idea to production-ready code:
- Langflow's visual drag-and-drop interface for building AI agents and workflows without extensive coding
- Pre-built NVIDIA AI Blueprints that reduce development time by up to 60%
- Integrated observability and evaluation through Arize to continuously monitor and improve performance
These tools democratize AI development across the organization, allowing more stakeholders to participate in the data flywheel by creating applications that generate valuable interaction data.
Powering the data flywheel
This three-layered architecture creates a self-reinforcing ecosystem that maximizes the value of enterprise data:
- Capture - The data layer efficiently ingests and stores diverse enterprise data—from customer interactions to operational metrics to proprietary content.
- Process - The knowledge layer transforms this raw data into embeddings, provides contextual understanding, and ensures appropriate guardrails.
- Build - The dev tools layer enables rapid creation of AI applications and agents that leverage this processed knowledge.
- Learn - As these applications interact with users, they generate new data that flows back into the data layer.
- Improve - This new interaction data is used to fine-tune models through NeMo Customizer, continuously improving performance.
- Repeat - The cycle continues, with each iteration strengthening the AI capabilities and generating more valuable data.
This unified architecture doesn't just support the data flywheel—it accelerates it. By combining DataStax's robust data platform (Astra DB, HCD), AI development tools (Langflow), and NVIDIA's advanced AI components (NeMo microservices), we've created an ecosystem where data and AI continuously improve each other, delivering ever-increasing value to the enterprise.
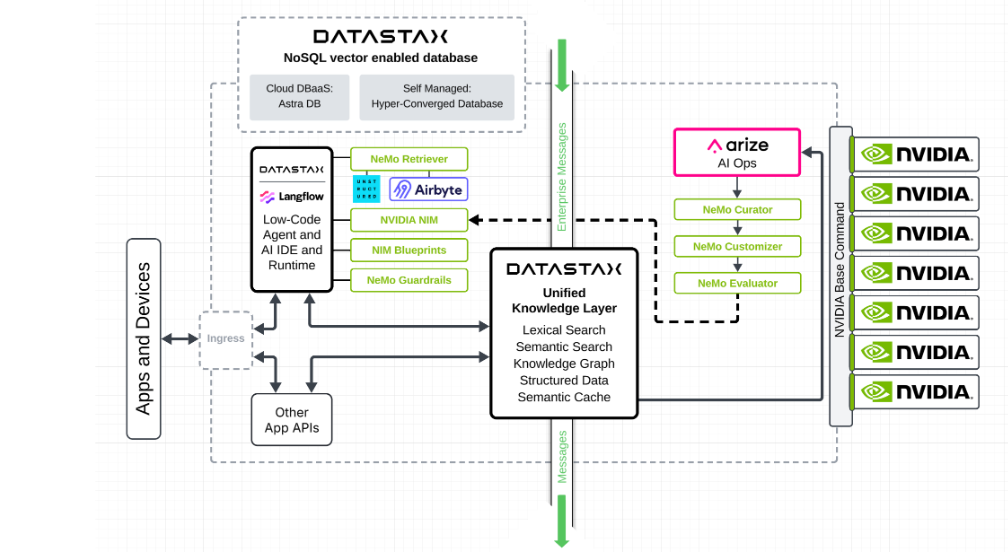
The diagram above illustrates our platform architecture, showing how it seamlessly combines DataStax core components with modules from Unstructured.io, Airbyte, Arize, and NVIDIA NeMo microservices. This modular approach gives enterprises the flexibility to leverage best-of-breed technologies while maintaining a cohesive, integrated experience that powers the data flywheel at every level.
Accelerating AI innovation together
Our journey with NVIDIA NeMo microservices demonstrates how strategic technology partnerships can dramatically accelerate innovation in the AI space. By integrating NeMo's capabilities into DataStax's data and AI platforms, we've created solutions that are greater than the sum of their parts—delivering measurable advantages for our customers:
- Speed to market - What would have taken years of internal development was accomplished in months through our collaboration with NVIDIA, enabling customers like Wikimedia Deutschland to launch their AI Knowledge Project 10x faster.
- Performance at scale - The benchmarks speak for themselves—19x faster throughput, 17x faster processing, and 80% lower costs compared to alternative solutions, all while maintaining enterprise-grade reliability.
- Continuous improvement - The data flywheel powered by our three-layer architecture ensures that AI applications don't just launch successfully—they get better over time, learning from every interaction to deliver increasingly relevant results.
As GenAI continues to evolve at breakneck speed, this partnership approach has proven invaluable. Rather than attempting to build everything in-house, we've leveraged NVIDIA's expertise in AI acceleration alongside our data management capabilities to create a platform that stays at the cutting edge without sacrificing stability or performance.
Looking ahead, the recent GA release of NVIDIA NeMo microservices opens up even more possibilities for our customers. With enhanced operational controls through Docker Compose and HELM charts, deployment automation, and fleet management capabilities, enterprises can now scale their AI initiatives with confidence, whether in the cloud or on-premises.
The DataStax AI Platform, built with NVIDIA AI, represents just the first chapter in our shared journey. As we continue to innovate together, we remain focused on our core mission: empowering organizations to harness the full potential of their data through AI, turning information into intelligence and intelligence into action—all while keeping your data where it belongs.
We invite you to join us on this journey and try Langflow. Whether you're just beginning to explore generative AI or looking to scale existing initiatives, the combined power of DataStax and NVIDIA provides the foundation you need to succeed in the AI-driven future.



