
Financial services institutions are racing to become AI-powered enterprises, aspiring to deliver instant credit decisions, proactive fraud prevention, automated claims processing, and hyper-personalized customer engagement through the power of generative AI. Yet behind every breakthrough AI capability lies a fundamental challenge: intelligence is only as good as the data that feeds it, and even with the right data, serving it to large-language models at the right time isn’t easy.
Many firms have conquered the basic LLM assistant, but that’s just the first step in getting transformative value from GenAI. Graduating to AI-native financial services requires rethinking their data strategy. AI-powered services have to be safe, relevant, and reliable. FSIs need a trusted foundation to protect their core systems while seamlessly serving their AI-enhanced digital applications: they need an AI-ready operational data layer.
What about all that modernization?
Most financial institutions spent the 2010s modernizing for cost and agility: migrating workloads to the cloud, containerizing applications, adopting microservices, and scaling APIs. Organizations invested heavily in data lakes to consolidate disparate information sources, implemented RESTful APIs to break down system silos, and adopted DevOps practices to accelerate deployment cycles. Reducing mainframe reliance was a major focus, moving some workloads to more cost-effective, globally distributed systems.
Throughout this modernization push, existing business logic and processes remained roughly the same. Data primarily served traditional analytics through batch ETL processes and business intelligence dashboards. On the application side, inspired by the likes of Uber and Netflix, modernization efforts did lead to more responsive customer experiences, including faster load times, smoother interfaces, and mobile-first design. However, the underlying business processes remained mostly unchanged; the focus was on improving the price-performance of the same services they’d offered for years.
Now, GenAI is demanding far more from this “modernized” data infrastructure than its architects envisioned. Even the “future-proof” NoSQL-powered operational data layers that drastically improved scalability and latency were not architected to support the surge of semantic similarity searches (a.k.a. vector searches) or the real-time retrieval that GenAI workloads now demand.
GenAI’s new demands
Unlike traditional machine learning models, which operated in controlled environments and relied on static or batch-updated datasets with pre-labeled data, AI agents today work in real time and rely on both structured and unstructured data. They must retrieve relevant information, compose responses, and take action all while adhering to strict regulatory frameworks, especially within the financial services industry.
Consider a customer asking an AI-powered assistant why a transaction was flagged for fraud, or whether a loan pre-approval is still valid. Answering accurately requires instant access to up-to-date account data, transaction history, and policy guidelines. It also demands an audit trail to prove that the recommendation was fair and compliant. If the AI assistant or AI-assisted customer service representative inadvertently exposes private account details, the reputational risk is immediate. An inaccurate recommendation can trigger not only customer dissatisfaction but regulatory scrutiny. And with respect to efficiency, these real-time AI interactions can't afford the latency and cost of mainframe queries.
These expectations set a new bar: real-time relevancy and accuracy is a must. And that requires AI-ready data infrastructure. For AI to operate responsibly and transparently, financial institutions need an operational data layer capable of delivering real-time, contextual, and governed information on demand.
Specifically, GenAI systems need these new capabilities beyond what the 2010’s “cost and efficiency” modern stack offered:
-
Low-latency access to contextual data to drive accurate, explainable decisions
-
Granular governance to comply with strict regulatory frameworks (e.g., GDPR, CCAR, Basel II/III)
-
Resilience so that bursts of AI-driven activity can be absorbed without compromising performance or reliability, while reducing strain on the system of record
-
Audit trails and traceability to prove why and how decisions were made
To succeed, financial services organizations must move beyond modernization and architect an operational data layer ready for AI at scale—without compromising trust, compliance, or customer confidence. This AI-ready operational data layer is the strategic foundation of the AI-powered enterprise.
What is the AI-ready ODL?
The AI-ready operational data layer must balance performance with governance, unlocking both innovation and accountability. Serving AI-powered applications demands instant response times, massive scale, and vector search while ensuring safety means that every decision is traceable to its source, every retrieval is logged, and every action is explainable.
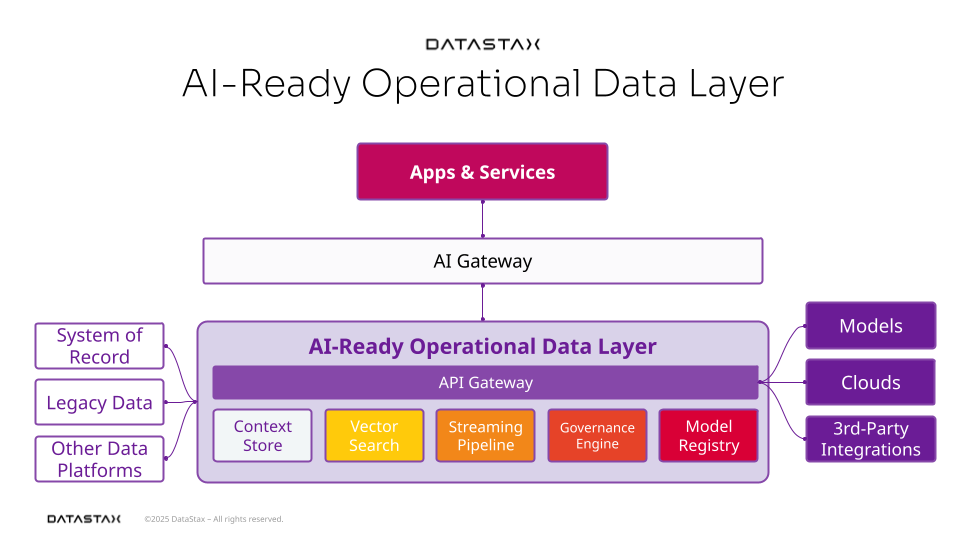
The AI-ready operational data layer includes:
-
Context store - Manages and serves real-time business context, user sessions, and interaction history to inform GenAI decisions by maintaining frequently accessed data in high-performance NoSQL databases, reducing expensive mainframe queries
-
Includes: NoSQL database like Astra DB
-
Vector search engine - Enables semantic search, similarity matching, and retrieval-augmented generation (RAG) for intelligent information discovery and assembly
-
Includes: Vector database, embedding generation service, RAG orchestration - all available in the DataStax AI Platform-as-a-Service
-
Streaming pipeline - Delivers real-time data to keep AI models aware of the latest transactions and interactions.
-
Includes: Event streaming, stream processing engine like Astra Streaming
-
Model registry - Centralizes AI model lifecycle management including versioning, metadata tracking, and deployment coordination
-
Includes: Model versioning, metadata catalog, deployment automation, performance monitoring
-
Governance engine - Enforces AI safety, compliance, and explainability through automated policies and comprehensive audit trails
-
Includes: Data lineage tracking, audit logging, safety guardrails, available through DataStax + NVIDIA NeMo guardrails
-
API gateway - Controls secure, scalable access to AI services and data across internal and external systems
-
Includes: Traffic routing, authentication, rate limiting, monitoring, security controls, like the DataStax Data API
These six components work together to create a unified, trusted foundation that transforms data from a static resource into an intelligent, responsive asset. Unlike traditional data infrastructure that focuses almost exclusively on efficient, cost-effective storage and retrieval, the AI-ready operational data layer treats data as a living system. It can understand context, maintain relationships, and adapt to real-time demands while preserving the trust and compliance that financial services require. This isn't just an upgrade to existing systems; it's a fundamental reimagining of how data serves intelligence.
From modernization to differentiation: Why financial services can't wait
The AI transformation in financial services isn't coming, it's here. Early movers are already capturing market share with AI-powered customer service, automated underwriting, and real-time fraud prevention.
The window for strategic advantage is rapidly narrowing. Boards are demanding AI capabilities with clear ROI timelines, competitors are shipping AI-powered features that reset customer expectations, and the institutions already building AI systems are accumulating the operational knowledge that will be difficult to fast track later.
Today is a great time to get started on your AI ODL
If you were to assess your current data infrastructure against GenAI’s new requirements, could you definitively say that you’re ready?
Can your systems deliver contextual insights in milliseconds? Do you have comprehensive audit trails for AI decisions? Can you scale vector search and streaming analytics without compromising security? These aren't future considerations, they're today's competitive requirements.
Becoming an AI-powered financial enterprise
Once your AI-ready operational data layer is in place, becoming an AI-powered financial enterprise shifts from aspiration to execution. Building AI-native applications becomes repeatable and scalable rather than one-off technical challenges. Capabilities like AI-powered fraud prevention that uses vector search to find and block fraudulent patterns in real-time, internal AI agents that enable customer service to resolve inquiries with full context in half the time (or less!), and instant loan decisions that consider dozens of risk factors simultaneously are now within reach (and don’t require the dreaded two-year project).
New AI workloads leverage the same foundational infrastructure: the context store for customer history and corporate knowledge, the vector search engine for intelligent document retrieval, the streaming pipeline for real-time data, the governance engine for audit trails and guardrails, and the model registry for lifecycle management. This AI-native architecture unlocks intelligent capabilities that traditional (and even 'modern') systems simply cannot support.
With your AI-ready operational data layer in place, you can rapidly deploy the intelligent services that will define your next century of providing trusted, proactive, and delightful financial services.
We’re here to help
Want help getting started on your AI ODL? Connect with DataStax AI and data experts to discuss your specific infrastructure needs and get a customized roadmap for enabling AI at scale in your financial institution.
Or, get started today with DataStax AI Platform-as-a-Service.
FAQs
How can machine learning help identify fraudulent transactions instantly?
Machine learning algorithms can analyze vast amounts of transaction data in real-time to identify patterns and anomalies that indicate fraudulent activity, enabling instant flagging of suspicious transactions before they complete. By continuously learning from historical transaction data and user behavior patterns, these systems can detect subtle deviations from normal spending habits, unusual merchant interactions, or suspicious timing patterns that would be impossible for human analysts to catch at scale.



