
If you've developed applications using Apache Cassandra® before, you know the drill: query patterns first, data modeling second, and forget about ad hoc queries unless you want to rewrite half your schema. Cassandra's performance and scale were always awesome — but only if you played by its strict, read-optimized rules.
But with Cassandra 5.0, things have changed. A LOT.
The biggest shift? Storage-attached indexes (SAI). It's not just another secondary index — it’s a whole new way to interact with your data. SAI gives developers the flexibility to query multiple columns with filtering, range conditions, and even better performance, all without having to bend your entire data model around your queries.
You can stop doing mental gymnastics just to store and retrieve your data. It's Cassandra like you've never seen before. It brings a much more developer-friendly experience to the table, while still keeping the scalability and resilience we all love.
Let’s show you what this means and why it is such a game changer. Let's go!
Movies galore
The examples in this post are based on movies because it's a dataset that most developers are already familiar with, especially with streaming services taking over the world.
The dataset including images used in this article were sourced from The Movie Database (TMDB), a community-built movie and TV database. Movies in the TMDB are uniquely identified by a movie ID and the corresponding IMDb ID for cross-referencing with the Internet Movie Database (IMDb), a popular online database of movies and TV shows.
In the example from TMDB below is the Netflix movie Extraction released in 2020. You can see from the screenshot under the movie title that it has a release date of April 24, the genres listed as "Action" and "Thriller", plus a runtime of 1 hour 56 minutes.
It shows the overview which is typically a brief description of the movie plot, and the cast which lists Chris Hemsworth in the leading role as Tyler Rake.
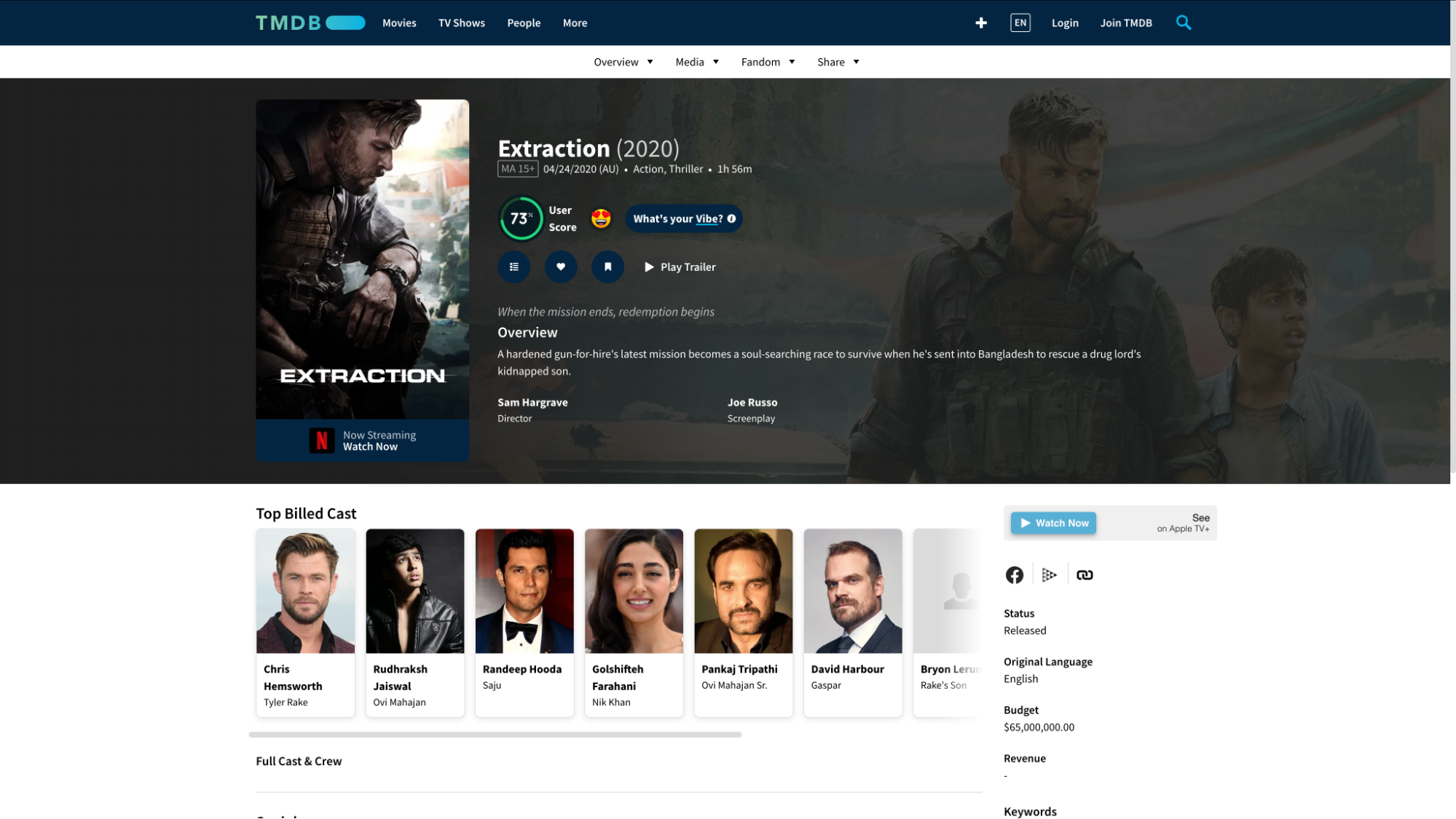
Note that for the purposes of this post, I only loaded a small subset of the data, or roughly 40K records out of over a million movies in the TMDB. This is to limit the number of rows returned in the examples to make it easier to view.
Traditional modeling
Our notional movies application retrieves details of a movie based on the movie's ID like:
GET movie details FOR movie id X
In Cassandra, we would model the data by partitioning the table on the movie ID [PRIMARY KEY (movie_id)]. It would look something like:
CREATE TABLE movies_by_id (
movie_id text,
cast map<text, text>,
genres set<text>,
imdb_id text,
overview text,
release_date date,
release_year int,
runtime int,
title text
PRIMARY KEY (movie_id)
)so the table can be queried with:
cql> SELECT * FROM movies_by_id WHERE movie_id = '545609';
But what if the application needed to retrieve the data in a different way? This is where it gets challenging for developers new to Cassandra. The idea that they can't just query a table with a filter on an ad hoc column is usually a surprise. Allow me to illustrate with these examples:
GET cast list beginning with lead actors FOR movie id X
GET list of movies FOR genre Y
Traditionally, we would have to design separate tables for these queries. In the case where the app needs a list of movie actors:
CREATE TABLE cast_by_movie (
movie_id text,
cast_order int,
actor_name text,
actor_id text,
character text,
release_year int STATIC,
title text STATIC,
PRIMARY KEY (movie_id, cast_order)
)To get the cast list for the movie Extraction:
cql> SELECT actor_name, cast_order, character
FROM cast_by_movie
WHERE movie_id = '545609';
movie_id | cast_order | actor | character
---------+------------+-------------------+------------
545609 | 1 | Chris Hemsworth | Tyler Rake
545609 | 2 | Rudhraksh Jaiswal | Ovi Mahajan
545609 | 3 | Randeep Hooda | Saju
<snip>To retrieve just the leading actor:
cql> SELECT actor_name, cast_order, character
FROM cast_by_movie
WHERE movie_id = '545609'
AND cast_order = 1;
movie_id | cast_order | actor | character
---------+------------+-------------------+------------
545609 | 1 | Chris Hemsworth | Tyler RakeThe schema for storing movies by genre would look something like:
CREATE TABLE movies_by_genre (
genre text,
movie_id text,
imdb_id text,
overview text,
release_year int,
title text
PRIMARY KEY (genre, movie_id)
)To retrieve the list of action movies:
cql> SELECT title, release_year, movie_id
FROM movies_by_genre
WHERE genre = 'Action';The next challenge for developers is keeping the three denormalised tables synchronized. An update to one table needs to be duplicated to the other two tables. In Cassandra this is achieved through a CQL BATCH update. Here is the example code in Java:
insertMovie = SimpleStatement.newInstance("INSERT INTO movies_by_id (...) VALUES (...)");
insertCast = SimpleStatement.newInstance("INSERT INTO cast_by_movie (...) VALUES (...)");
insertGenre = SimpleStatement.newInstance("INSERT INTO movies_by_genre (...) VALUES (...)");
batch = BatchStatement.newInstance(
insertMovie,
insertCast,
insertGenre);
session.execute(batch);If you find the above daunting—whether you're new to Cassandra or not—let me tell you it doesn't have to be, because there's a simpler way.
Enter Cassandra 5.0
One of the most anticipated features is storage-attached indexing for a very good reason. SAI enables query patterns which are much more flexible and performant, requires less coding, and provides an accelerated path to extending application functionality.
DataStax has been working on SAI for several years; it’s been deployed in Astra DB for some time, and its reliability and performance has been getting high marks from end users.
SAI was donated to the Apache Software Foundation (ASF) back in 2020 as Cassandra Enhancement Proposal CEP-7. It was planned to be implemented in two stages with so-called version 1 features included in Cassandra 5.0. SAI version 2 features are slotted to be included in the next major release (planned) which means that some examples in this post will not work in version 5.0, particularly SAI queries using the OR (union) operator and range queries on some data types.
While we're on the subject, Astra DB has the most complete version of SAI, with the same feature-complete version deployed on both DataStax Enterprise (DSE) and Hyper-Converged Database (HCD) – all built on Apache Cassandra.
Query your way
We can query a table with a filter on any column if it is indexed by SAI. This reduces the complexity of having to design a data model for each application query and removes the need to keep multiple denormalised tables synchronised client-side so there is less code to write and maintain.
If for example we wanted to query by the movie title, we just need to index the title column:
cql> CREATE CUSTOM INDEX ON movies_by_id (title)
USING 'StorageAttachedIndex';To retrieve movies with the title "Extraction":
cql> SELECT title, release_year, movie_id, imdb_id
FROM movies_by_id
WHERE title = 'Extraction';
title | release_year | movie_id | imdb_id
------------+--------------+----------+-----------
Extraction | 2015 | 326425 | tt4382872
Extraction | 2013 | 218381 | tt2823574
Extraction | 2020 | 545609 | tt8936646From the example output above, there are three movies sharing the exact same title but released in different years. The movie from 2013 stars Danny Glover and Vinnie Jones, while the 2015 version stars Bruce Willis and Kellan Lutz:

Similarly, we can create an SAI index on the release_year column:
cql> CREATE CUSTOM INDEX ON movies_by_id (release_year)
USING 'StorageAttachedIndex';which would allow us to retrieve the list of movies released in 2013:
cql> SELECT title, release_year, movie_id, imdb_id
FROM movies_by_id
WHERE release_year = 2013
LIMIT 3;
title | release_year | movie_id | imdb_id
----------------+--------------+----------+-----------
Green Street 3 | 2013 | 182873 | tt2628316
Something Good | 2013 | 236329 | tt2542502
Fright Night 2 | 2013 | 214597 | tt2486630Range queries
The unique implementation of indexing numeric types as a balanced binary search tree with postings at both internal and leaf nodes enables extremely efficient retrieval of results.
Range queries using SAI indexes use syntax familiar to developers. For example, to get a list of movies released after 2024:
cql> SELECT title, release_year, movie_id, imdb_id
FROM movies_by_id
WHERE release_year > 2024
LIMIT 3;
title | release_year | movie_id | imdb_id
----------------+--------------+----------+------------
Yunan | 2025 | 1189738 | tt24022322
Inside | 2025 | 1225582 | tt29424168
Le Marsupilami | 2026 | 1145899 | tt33029380SAI also allows more complex range queries using intersection (AND) and union (OR) boolean operators in a single pass. For example, if we index the release date:
cql> CREATE CUSTOM INDEX ON movies_by_id (release_year)
USING 'StorageAttachedIndex';then we can get a list of movies released in the second half of April 2020:
cql> SELECT title, release_date, movie_id, imdb_id
FROM movies_by_id
WHERE release_date >= '2020-04-15'
AND release_date <= '2020-04-30';
title | release_date | movie_id | imdb_id
-------------+--------------+----------+------------
Extraction | 2020-04-23 | 545609 | tt8936646
Gutted | 2020-04-17 | 1286694 | tt10768652
Bad Therapy | 2020-04-17 | 527382 | tt8488518Indexing on steroids
SAI is backed by Apache Lucene™️so we can level up the indexes using built-in analyzers from Lucene. For example, we can index the movie titles using the built-in STANDARD analyzer which splits text into "words" (tokens) and converts them into lowercase. Note that you will need to drop the index on a column if one already exists using the CQL DROP INDEX command before you can reindex the column.
cql> CREATE CUSTOM INDEX ON movies_by_id (title)
USING 'StorageAttachedIndex'
WITH OPTIONS = { 'index_analyzer': 'STANDARD'};In a previous example, we retrieved a list of movies which were titled "Extraction" which is a filter for an exact match for the term "Extraction". With the STANDARD analyzer, we can get a list of movies whose title contains the term "extraction" (not just an exact match):
cql> SELECT title, release_year, movie_id
FROM movies_by_id
WHERE title:'extraction';
title | release_year | movie_id
----------------------------------+--------------+----------
Extraction | 2015 | 326425
Extraction 2 | 2023 | 697843
Extraction | 2013 | 218381
Extraction | 2020 | 545609
Predators: Moments of Extraction | 2010 | 704882Note the use of the SAI operator (:) in the WHERE clause food querying "analyzed" indexes instead of the equality (=) operator.
Text analyzers
Lucene analyzers enable us to extract index terms from text similar to full-text search engines such as Apache Solr™️ and Elasticsearch. Analyzers enable term matching on strings and makes it easier to find relevant rows in a table.
The generic analyzers include standard (used in the example above), simple (uses letter tokenizer with lowercase filter), whitespace, stop, and lowercase.
There are specific analyzers for over 30 languages that include Arabic, Bulgarian, Dutch, Hindi, Irish, and Persian. There are 14 available tokenizers (these split text into words or tokens) which include standard, classic, nGram, and wikipedia.
Supported CharFilters are cjk, htmlstrip, mapping, persian, and patternreplace. There are over a hundred token filters with lowercase, classic, N-Grams, and stemmers among some of the most popular.
Stemmers normalise terms into base words by removing suffixes so words like "jumps" and "jumping" are transformed into "jump". We can recreate the index on the movie titles and add the Porter stemming filter to illustrate how it significantly extends SAI's capabilities:
cql> CREATE CUSTOM INDEX ON movies_by_id (title)
USING 'StorageAttachedIndex'
WITH OPTIONS = {
'index_analyzer' : '{
"tokenizer" : {"name":"standard"},
"filters" : [
{"name":"lowercase"},
{"name":"porterstem"}
]
}'
};A query for "extraction" (all lowercase) reduces the search term to its base form "extract":
cql> SELECT title, release_year
FROM movies_by_id
WHERE title:'extraction';
title | release_year
-------------------------------------+--------------
Extracted | 2012
Extraction | 2015
Extraction 2 | 2023
Extract | 2009
Extract: Mike Judge's Secret Recipe | 2009
Extraction | 2013
Extraction | 2020
Predators: Moments of Extraction | 2010and we now get matches for not just "extraction" but also for "extract" and "extracted" in the results:

Working with CQL collections
In traditional data modeling, previously we had to create a new table that is partitioned by genres so we can get a list of action movies, for example. But with SAI, we can simply index the genres column and as you'll see from the example syntax below there is nothing special about indexing a CQL set collection:
cql> CREATE CUSTOM INDEX ON movies_by_id (genres)
USING 'StorageAttachedIndex';Now that we have indexed it with SAI, we can query for action movies with a filter using the CONTAINS operator:
cql> SELECT title, release_year, genres
FROM movies_by_id
WHERE genres CONTAINS 'Action'
LIMIT 5;
title | r_year | genres
-------------------+--------------+------------------------
Narasimhudu | 2005 | {'Action'}
Mad Dog Time | 1996 | {'Action', 'Comedy', 'Crime'}
Pipe Nation | 2023 | {'Action'}
Kaala Sona | 1975 | {'Action', 'Western'}
Soldier's Revenge | 1986 | {'Action', 'Drama', 'War'}How about searching for movies by the actor's name? Yes, we can!
The cast column is a CQL map where the key is the movie character's name and the value is the actor's name. If we want to filter by the actor's name, we need to index with VALUES() function:
cql> CREATE CUSTOM INDEX ON movies_by_id (VALUES(cast))
USING 'StorageAttachedIndex';and now we can get a list of movies that stars Chris Hemsworth with a filter using the CONTAINS operator:
cql> SELECT title, release_year
FROM movies_by_id
WHERE cast CONTAINS 'Chris Hemsworth'
LIMIT 5;
title | release_year
-----------------------------+--------------
Red Dawn | 2012
Doctor Strange | 2016
Snow White and the Huntsman | 2012
Avengers: Age of Ultron | 2015
Blackhat | 2015
If we index the map keys (with KEYS()):
cql> CREATE CUSTOM INDEX ON movies_by_id (KEYS(cast))
USING 'StorageAttachedIndex';we can get a list of movies that feature the character "Thor" with a filter using the CONTAINS KEY operator:
cql> SELECT title, release_year
FROM movies_by_id
WHERE cast CONTAINS KEY 'Thor'
LIMIT 5;
title | release_year
-----------------------------+--------------
Avengers: Age of Ultron | 2015
George of the Jungle | 1997
Damsels in Distress | 2012
Thor: The Dark World | 2013
Thor: Ragnarok | 2017Multi-term search
SAI uses a query plan that provides the ability to filter on multiple indexed columns with the intersection (AND) and union (OR) boolean operators in a single query, for example:
cql> SELECT title, release_year, movie_id, imdb_id
FROM movies_by_id
WHERE title:'extraction'
AND release_year = 2020;
title | release_year | movie_id | imdb_id
------------+--------------+----------+-----------
Extraction | 2020 | 545609 | tt8936646Similarly, we can query for movies which are in both the action and thriller genres:
cql> SELECT title, release_year, genres
FROM movies_by_id
WHERE genres CONTAINS 'Action'
AND genres CONTAINS 'Thriller'
LIMIT 3;
title | genres
------------------+----------------------------------
The Lost Tribe | {'Action', 'Horror', 'Thriller'}
Mail Order Bride | {'Action', 'Comedy', 'Thriller'}
Spy Hunt | {'Action', 'Crime', 'Thriller'}Finally, here's a more complex query with nested brackets which searches for movies with "extraction" and "avengers" in the title and stars Chris Hemsworth:
cql> SELECT title, release_year, movie_id
FROM movies_by_id
WHERE (title:'Extraction' OR title:'Avengers')
AND cast CONTAINS 'Chris Hemsworth';
title | release_year | movie_id
-------------------------+--------------+----------
Avengers: Age of Ultron | 2015 | 99861
Extraction 2 | 2023 | 697843
Avengers: Doomsday | 2026 | 1003596
Avengers: Endgame | 2019 | 299534
Extraction | 2020 | 545609
The Avengers | 2012 | 24428
Avengers: Infinity War | 2018 | 299536What's next?
In an upcoming post, I'll show you how SAI can level up your applications with Generative AI so you can "talk" to your data using natural language. You'll be able to retrieve data from Cassandra with a query like "superhero movies with strong female leads!"

In the meantime, check out the SAI Quickstart Guide plus SAI examples and try Astra DB for free—or book a demo with our data architects for a guided tour of SAI in action!



