
Astra DB is a high-performance NoSQL database powered by Apache Cassandra® with built-in vector search, but that's just what the product page says. Not everything fits onto one page, so I wanted to share a few things that you might not already know about Astra DB and how it helps you to build accurate, low-latency, retrieval-augmented generation (RAG) powered generative AI apps.
Astra DB can create vector embeddings for you
When ingesting data for a RAG application, there are several steps you need to take: document loading, text parsing, chunking text, creating vector embeddings, and storing it in the database. Astra DB can simplify the process by combining those last two steps.
Astra Vectorize can create vector embeddings for your text chunks at the point of inserting them into the collection.
When you create an Astra DB collection, you can choose one of the supported embedding models. There are models available from OpenAI (including Azure OpenAI), Voyage AI, Mistral AI, Jina AI, and Upstage. Astra DB also hosts NVIDIA embedding models that run in the same environment as the database, boosting performance—Wikidata reduced their data ingestion time from 30 days to two with Vectorize—and ensuring the data never leaves the database.
Once you have set up your collection with your embedding provider of choice, ingesting data with Vectorize is a case of providing the text you want turned into a vector as a special $vectorize property in the documents you are storing. In TypeScript, this looks like:
import { DataAPIClient } from "@datastax/astra-db-ts";
const client = new DataAPIClient(process.env.ASTRA_DB_APPLICATION_TOKEN);
const db = client.db(process.env.ASTRA_DB_API_ENDPOINT);
const collection = db.collection(process.env.ASTRA_DB_COLLECTION);
await collection.insertOne({
$vectorize: "A robot may not injure a human being or, through inaction, allow a human being to come to harm."
});Then to perform a vector search against this collection you use the $vectorize field to sort by your query.
const cursor = collection.find({}, {
sort: { $vectorize: "Are robots allowed to protect themselves?" },
limit: 5,
});
const results = await cursor.toArray();You can learn more about Astra Vectorize in the documentation.
Astra DB supports graph RAG
Depending on your data, regular vector search can sometimes miss context, which makes it harder for large language models (LLMs) to answer certain queries. Graph RAG is a technique that takes your documents, extracts links between them, and uses those links to retrieve extra contextual information at the retrieval stage. Providing extra linked context to an LLM makes for more accurate and informed answers.
Astra DB supports graph RAG via LangChain. You can replace the AstraDBVectorStore with AstraDBGraphVectorStore and ensure you ingest your data in a way that extracts the links between documents. A simplified ingestion example that reads a URL, extracts HTML links, strips the HTML, and splits the text into chunks before storing in Astra DB (using Astra Vectorize to create embeddings) might look like this:
import os
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import AsyncHtmlLoader
from langchain_community.graph_vectorstores.extractors import (
HtmlLinkExtractor,
LinkExtractorTransformer
)
from langchain_community.document_transformers import BeautifulSoupTransformer
from langchain_astradb import AstraDBGraphVectorStore, CollectionVectorServiceOptions
vectorize_options = CollectionVectorServiceOptions(
provider="nvidia",
model_name="NV-Embed-QA",
)
vector_store = AstraDBGraphVectorStore(
collection_name="graph",
token=os.environ.get("ASTRA_DB_APPLICATION_TOKEN"),
api_endpoint=os.environ.get("ASTRA_DB_API_ENDPOINT"),
collection_vector_service_options=vectorize_options
)
urls = [
"https://www.datastax.com/guides/graph-rag",
"https://www.datastax.com/blog/build-graph-rag-with-unstructured-and-astra-db"
]
loader = AsyncHtmlLoader(urls)
docs = loader.load()
transformer = LinkExtractorTransformer([HtmlLinkExtractor().as_document_extractor()])
bs4_transformer = BeautifulSoupTransformer()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
docs = transformer.transform_documents(docs)
docs = bs4_transformer.transform_documents(docs)
chunks = text_splitter.split_documents(docs)
vector_store.add_documents(chunks)Then to search Astra DB, you can use the graph store's traversal_search method to first retrieve a number of document chunks (k), before traversing the graph to the specified depth for additional chunks. In this case, we perform the search initially finding four chunks using a similarity search and then traversing the graph to a depth of two to return related chunks.
traversal_results = vector_store.traversal_search(
query="What are the differences between Graph RAG and naive RAG?",
k=4,
depth=2,
)Check out this full tutorial on building graph RAG with Unstructured and Astra DB.
Astra DB supports ColBERT
Graph RAG can help if your context is spread across chunks, but there are other situations where graph RAG won't necessarily help. If your data contains terms that aren't in the training data of your embedding model, it can be difficult to get accurate similarity search results.
One way to overcome this is to use ColBERT. ColBERT creates a vector per token in a body of text, creating a sliding window of context over entire passages and capturing unknown context much better. This does require more storage for the extra vectors, but if accuracy is your priority, it’s worthwhile.
You can use ColBERT with Astra DB in LangChain by using the RAGStack implementation.
To ingest the data, you can use the ColbertEmbeddingModel and ColbertVectorStore.
import os
from ragstack_colbert import CassandraDatabase, ColbertEmbeddingModel, ColbertVectorStore
embedding = ColbertEmbeddingModel()
database = CassandraDatabase.from_astra(
astra_token=os.environ.get("ASTRA_DB_APPLICATION_TOKEN"),
database_id=os.environ.get("ASTRA_DB_DATABASE_ID"),
keyspace="default_keyspace"
)
vector_store = ColbertVectorStore(
database=database,
embedding_model=embedding
)
results = vector_store.add_texts(texts=YOUR_LIST_OF_TEXTS, doc_id="myDocs")Then performing a similarity search is pretty much the same as any other vector store search in LangChain.
from ragstack_colbert import CassandraDatabase, ColbertEmbeddingModel
from ragstack_langchain.colbert import ColbertVectorStore as LangchainColbertVectorStore
colbert_embedding = ColbertEmbeddingModel()
colbert_database = CassandraDatabase.from_astra(
astra_token=YOUR_ASTRA_DB_TOKEN,
database_id=YOUR_ASTRA_DB_ID,
keyspace="default_keyspace"
)
vector_store = LangchainColbertVectorStore(
database=colbert_database,
embedding_model=colbert_embedding
)
query = "What is ColBERT?"
results = vector_store.similarity_search(query)Check out this full tutorial on using ColBERT with Astra DB, or for a faster alternative, Jonathan Ellis's ColBERT Live!, which uses Answer AI's colbert-small-v1 model and is supported by Astra DB.
Astra DB indexes your vectors live
Your vector database needs to be both accurate and speedy in order to ensure the performance of your application. When you are ingesting or updating data in your collection, rebuilding the index takes time and leaves you with slow queries or out of date data.
Astra DB's vector indexing capabilities are a combination of Cassandra's storage-attached indexing (SAI) and JVector, a non-blocking, concurrent, graph-based vector index. What this means is that Astra DB doesn't need to rebuild or block access to its index when you are inserting vectors, they are updated live.
The upshot of this is high throughput and accuracy even under mixed loads of reads and writes. Check out this benchmark of throughput and accuracy against Pinecone, particularly when Pinecone is performing indexing. Astra DB doesn't sacrifice throughput or accuracy under load; it will always be there for your application.
Astra DB is integrated in all your favourite frameworks
We've seen so far in this post that Astra DB is available in LangChain, but you can also find it in:
- LangChain.JS
- LlamaIndex and LlamaIndex.TS
- Haystack
- Mastra (a newer framework, built by the team behind Gatsby)
And of course Astra DB is integrated into Langflow. Deeply integrated! Once you enter your application token into the Astra DB component, your databases will automatically load. Then once you select your database, you can pick the collection you need too.
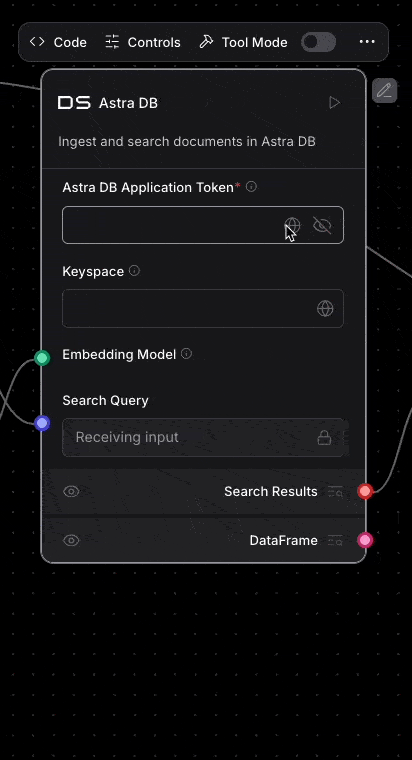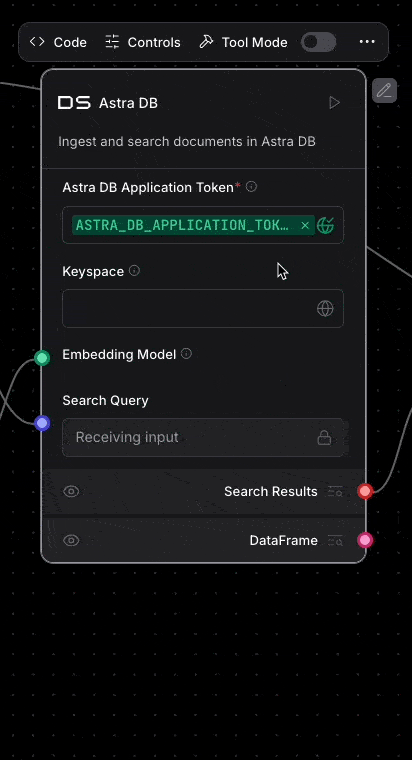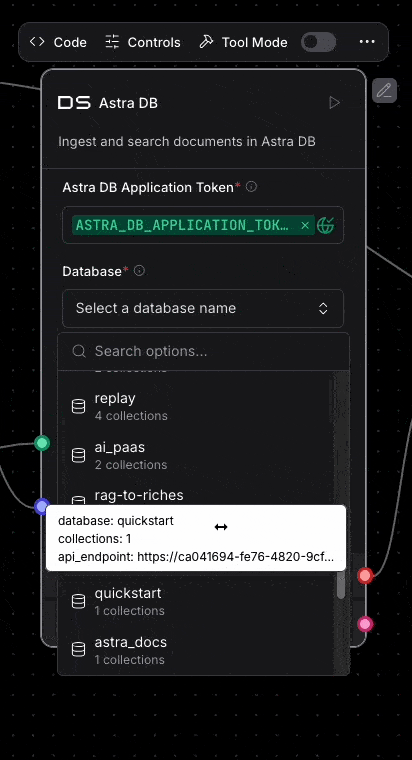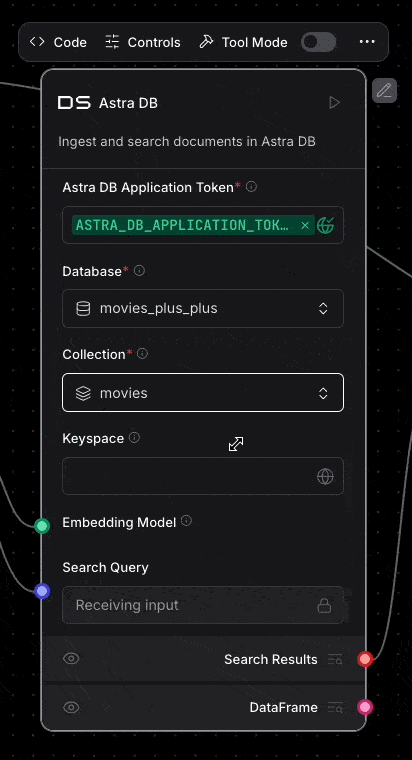
You can even create a new database from within Langflow. Oh, and Langflow supports using Astra Vectorize when ingesting or performing vector search too.
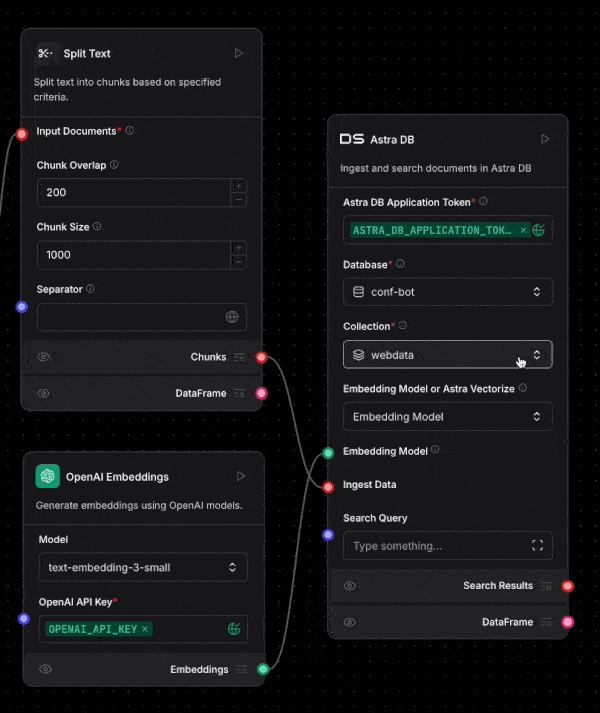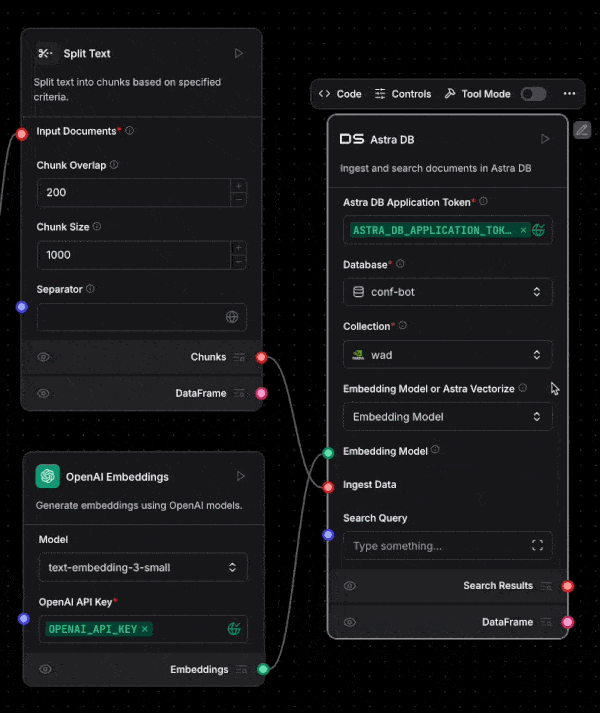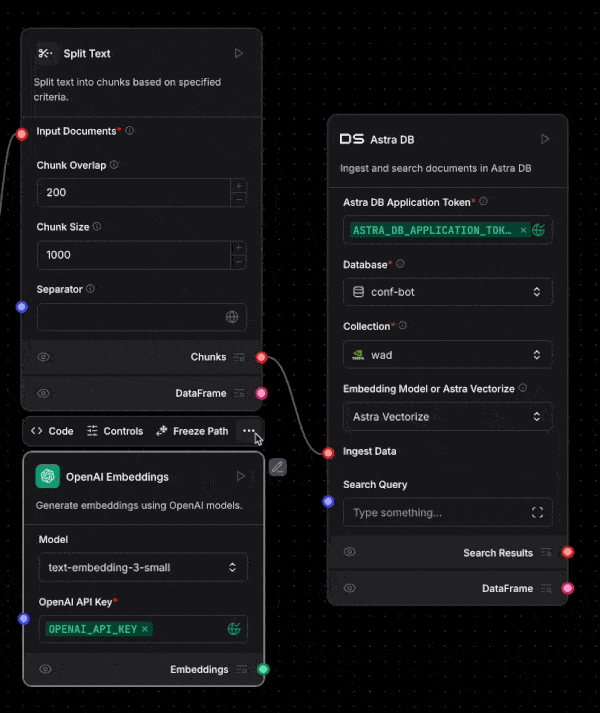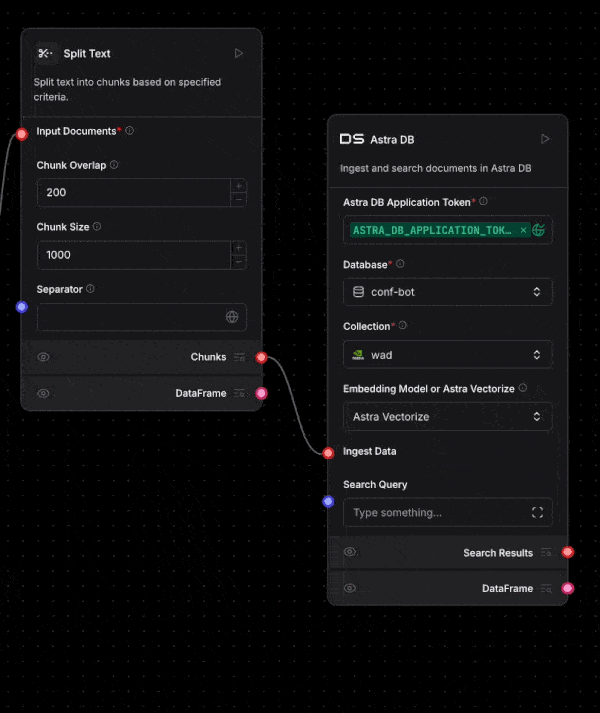
Langflow is a great visual way to build agents, and Astra DB makes it easy to build RAG or agentic RAG within Langflow.
Astra DB is ready to help you build transformative AI
Whether you're looking to build with Langflow or any number of other frameworks, or try out alternative vector searches like graph RAG or ColBERT, Astra DB is there to help. And it will do it quickly, creating vectors for you via Vectorize and indexing them live so your data is always up to date.
There are so many different applications you can build; check out examples like this AI resume assistant, RAG-powered voice agent, or hum-to-search music recognition app, all powered by Astra DB.
From chat bots to autonomous agents, Astra DB supports you in building the GenAI apps that are going to transform your business.



