
The introduction of Astra DB Hybrid Search to the DataStax Data API adds significant new potential in terms of improving the accuracy of vector-based search results, and in turn, building innovative new generative AI applications. We’ve added a host of improvements to increase accuracy that are available in our low-code development platform Langflow.
It’s incredibly easy to leverage them; here’s an example of how one could build a GenAI workflow simply and easily.
Hybrid Search Template
This post introduces our Hybrid Search Template for Langflow. It doesn’t attempt to dive into the theory of hybrid search, nor does it explain the underlying details of the Data API. These details are available in the DataStax documentation.
Instead, we’ll turn our focus to Langflow and how we can quickly build a pipeline that takes advantage of Hybrid Search. It’s actually quite straightforward with a combination of components, including Astra DB Hybrid Search, and some processing of the inputs and outputs.
The easiest way to start using Hybrid Search with Astra DB is to download and install Langflow Desktop. Alternatively, for an open-source installation, you can download Langflow from GitHub. Next, download the flow here, and import it by creating a blank flow in Langflow and choosing “Import” from the top menu bar.
The flow should be pre-configured with a read-only key that has access to a hosted DataStax collection. You simply need to provide an OpenAI key in the two OpenAI Model components to get started.
Let’s take a zoomed out look at the full flow:
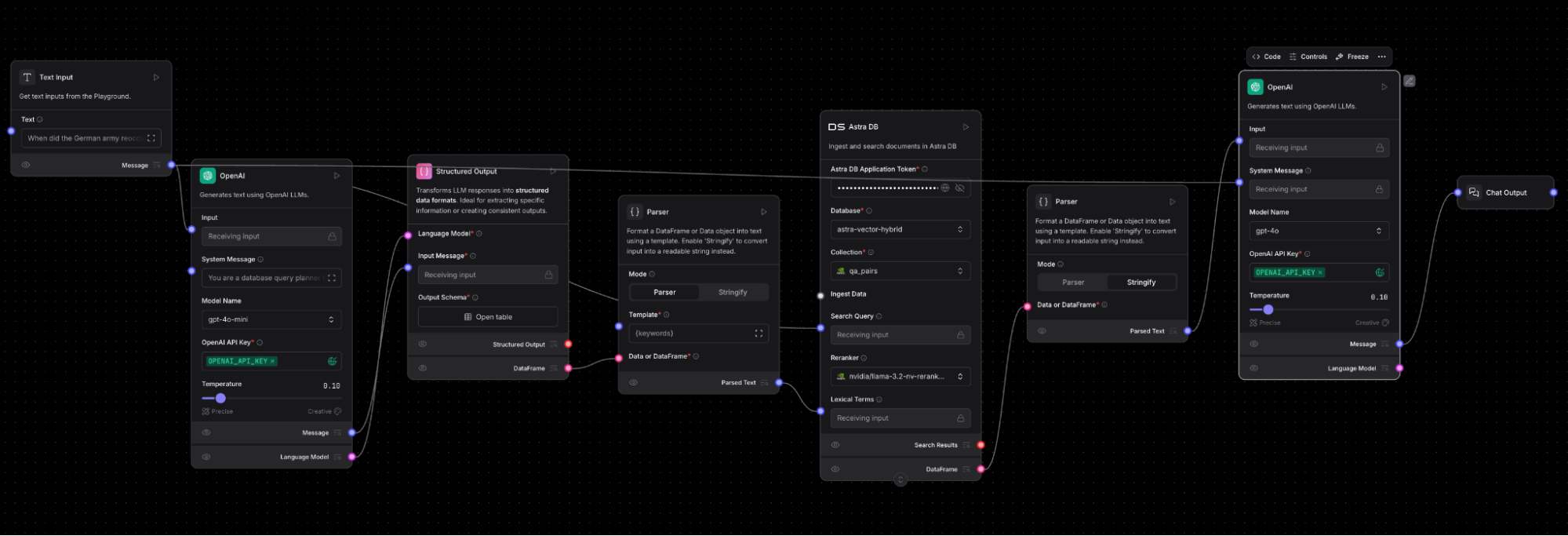
The flow begins with a Text Input, which asks a rather simple question: “When did the German army reoccupy Rhineland?” This question is derived directly from the popular SQuAD dataset.
The Text Input is attached to the Astra DB component as the Search Query. This is the standard vector search approach: a query is converted to a vector, and the similarity to pre-existing vectors is computed in order to derive the question-and-answer pairs that are most relevant in terms of answering the question. In this case, the question matches exactly, so we’d certainly hope and expect that the relevant row comes up first. It’ll be even more interesting to see what other search results might be viewed as similar to the provided question.
Now we introduce Hybrid Search with a lexical term field. Let’s zoom into that portion of the flow:
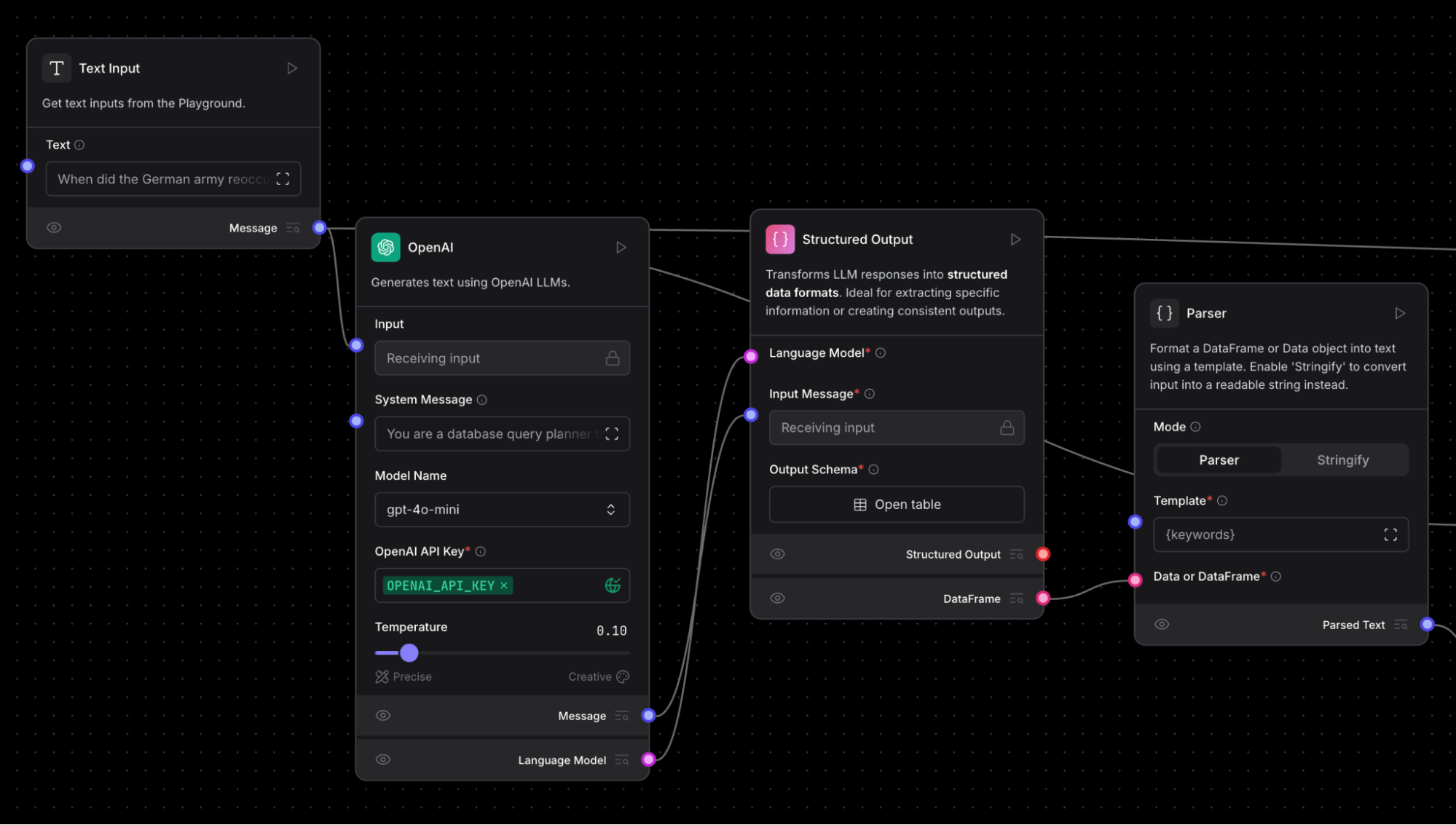
We pipe the input question into an LLM (in this case OpenAI). We instruct the LLM to perform this task:
“You are a database query planner that takes a user request, and converts it to a search against the subject matter in question.You should convert the query into:1. A list of keywords to use against a Lucene text analyzer index, no more than 4. Strictly unigrams. 2. A question to use as the basis for a QA embedding engine. Avoid common keywords associated with the user's subject matter.”
This enables us to produce lexical terms, which can refine the search results returned by the Astra DB component using Hybrid Search. In this instance, the LLM produces the terms: German, army, reoccupy, Rhineland. Now, when we take a look at the search results returned by Astra DB Hybrid Search, we see these as the top results:
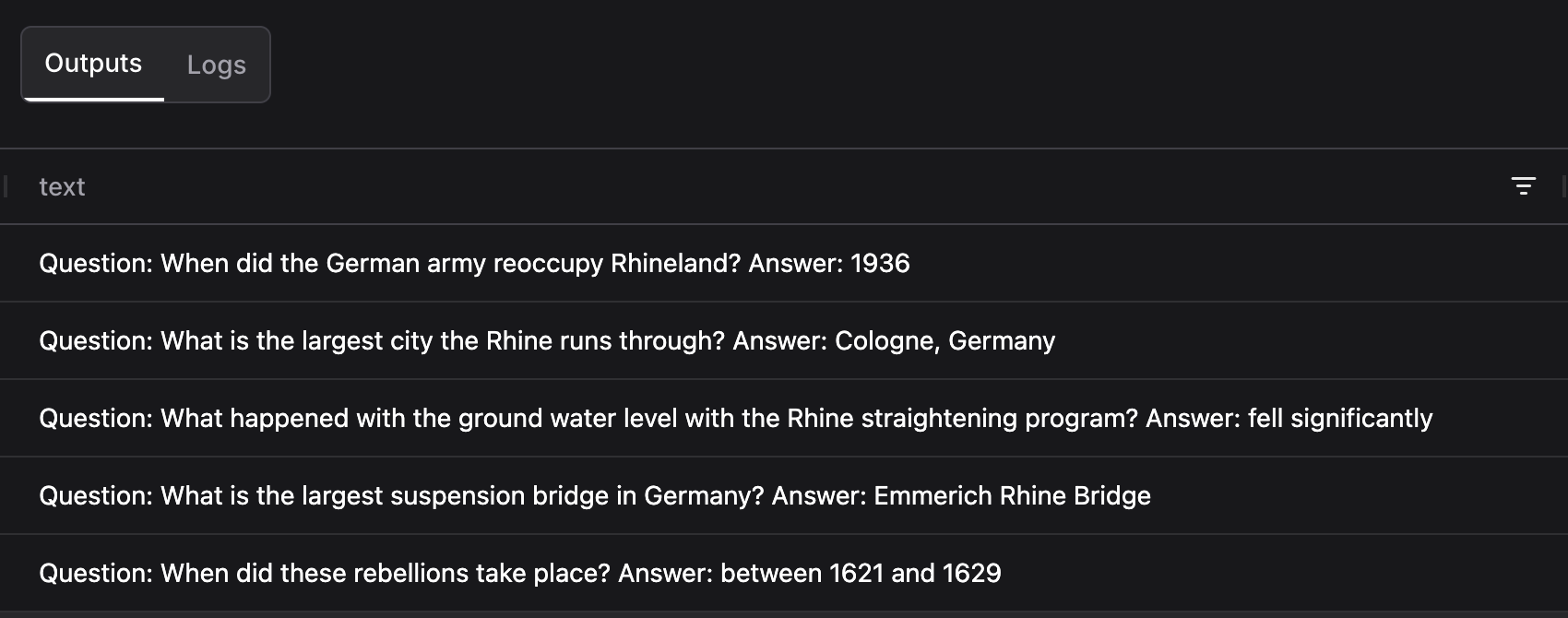 As you can see, we get both the answer to our question, but also several questions that are clearly related - several involving the Rhine, and another involving a rebellion, which the search algorithm identifies as being related to an army reoccupation. With quality search results, we can inspect the remainder of the flow to see how we process them downstream:
As you can see, we get both the answer to our question, but also several questions that are clearly related - several involving the Rhine, and another involving a rebellion, which the search algorithm identifies as being related to an army reoccupation. With quality search results, we can inspect the remainder of the flow to see how we process them downstream:
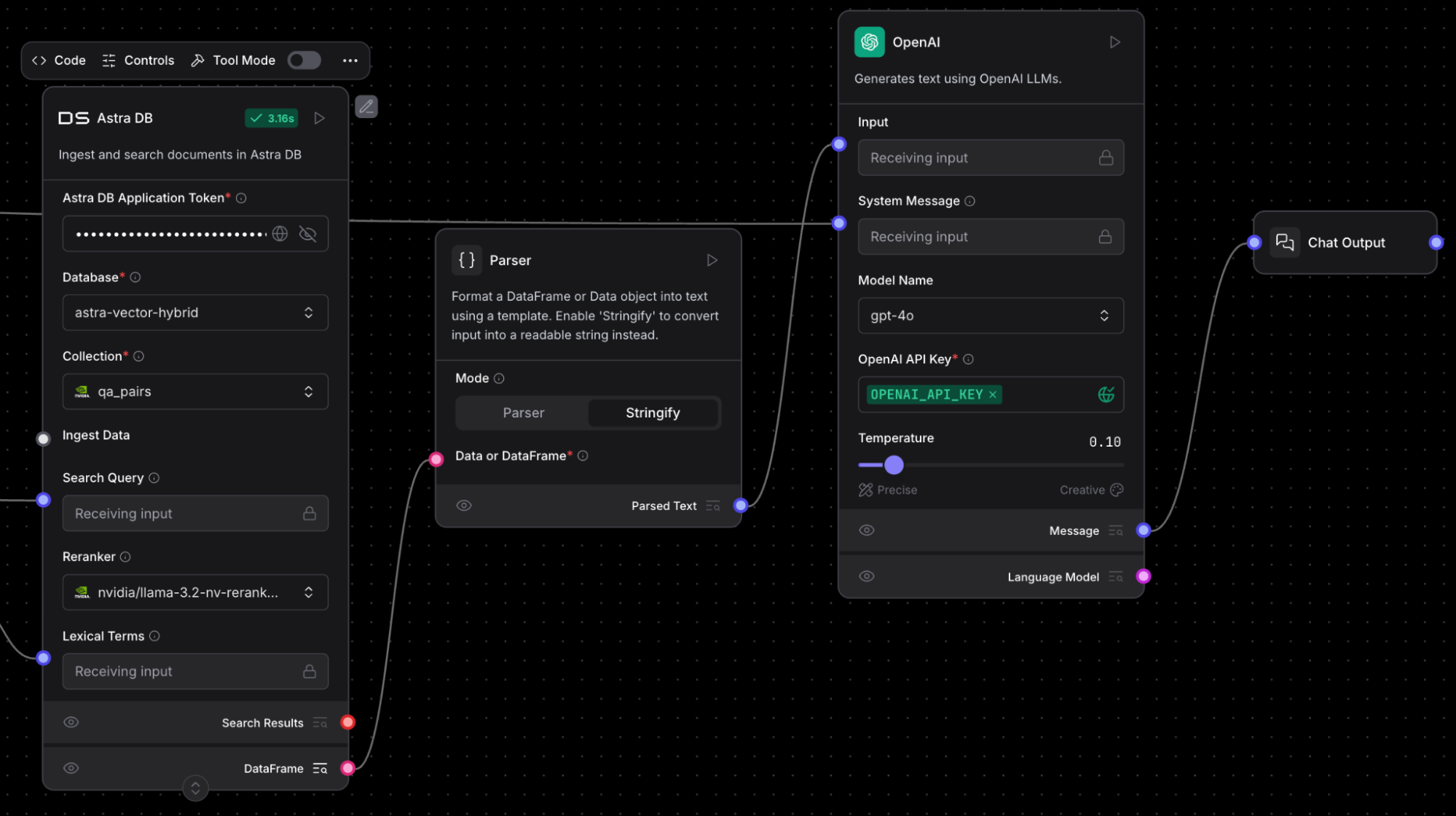 The DataFrame shown above is parsed into a string containing all the search results in the provided order, then the input is passed to another OpenAI LLM. The OpenAI LLM also receives the original question, and uses the search results to provide an answer, which gets passed to the Chat Output in Langflow. When you run the flow from the playground, you see this output:
The DataFrame shown above is parsed into a string containing all the search results in the provided order, then the input is passed to another OpenAI LLM. The OpenAI LLM also receives the original question, and uses the search results to provide an answer, which gets passed to the Chat Output in Langflow. When you run the flow from the playground, you see this output:

An easy and powerful framework
Ultimately, Hybrid Search is a refinement of the vector search algorithms supported by Astra DB. Depending on the use case, this refinement can be smaller or larger, but when those use cases present themselves, an easy framework for building out AI workflows that Langflow provides is immensely powerful, both for rapid prototyping and for production use cases. This template can be downloaded from here, and we hope can be a springboard for other innovative flows that take advantage of the Hybrid Search refinements built into Astra DB.



