
As an appetizer for 5 Days of Accuracy next week, here's a post we co-authored with Unstructured, a DataStax partner that simplifies a key ingredient of AI accuracy: turning messy, scattered information into organized, usable data.
Retrieval-augmented generation (RAG) has emerged as a powerful method for enhancing the accuracy and contextual relevance of generative AI outputs. Traditional approaches have primarily relied on semantic similarity search within vector stores. While effective, this approach has inherent limitations. It can miss nuanced contextual relationships or structured associations between documents.
Graph-based RAG methods, which integrate RAG techniques with knowledge graphs in various ways, promise greater precision but have been notoriously challenging to implement. Traditionally, constructing, navigating and maintaining these “knowledge graphs” was difficult. It involved manual extraction of structured relationships from documents, inflexible static graph databases and dedicated graph database infrastructure.
Fortunately, recent advancements — particularly tools like Unstructured and the newly-released Graph Retriever library — have greatly simplified these workflows. Unstructured provides push-button transformation of unstructured documents into structured, graph-ready data, using custom prompting of advanced large language models (LLMs) for automated entity extraction and vector databases for storage. The Graph Retriever library then dynamically constructs graph-based queries over these metadata-rich vector stores, eliminating the need for dedicated graph databases.
Here, we’ll explore a new generation of tools that simplify graph RAG by walking through an example application. The code for this example is available as a notebook.
How graph RAG works
Graph RAG uses many of the same tools and techniques as traditional semantic similarity-based RAG, but also adds some important features:
- Documents are enriched with structured metadata, such as entities (people, locations, organizations).
- A graph is dynamically built based on this structured metadata, capturing explicit relationships between documents.
- Retrieval occurs by traversing these structured connections, enabling more contextually relevant document retrieval.
This structured approach provides superior context navigation, enabling applications to fetch documents related not merely semantically but based explicitly on relationships and entities present in the metadata.
The Role of Unstructured and the Graph Retriever Library
As with most AI/ML problems, high-quality data is essential. In graph RAG, having accurate metadata for each document or document chunk is crucial, because metadata is the basis for building and using the knowledge graph. Traditionally, assigning metadata has been similar to manually labeling a data set, but Unstructured provides extensive and extensible metadata out of the box. With enrichments to standard ETL (extract, transform, load) such as custom prompting, Unstructured uses LLM-based named entity recognition (NER) to automatically generate metadata key-value pairs. This, in turn, enhances the accuracy of retrieval.
Unstructured’s ETL+ for GenAI continuously harvests newly generated unstructured data from systems of record, transforming it into LLM-ready formats using optimized, pre-built pipelines and writing it to DataStax Astra DB. You can deploy complete ingestion and preprocessing pipelines in seconds, with configuration options and third-party integrations for the partitioning, enrichment, chunking and embedding steps. This enables knowledge graph building without needing to write any code or create any custom steps. The critical NER enrichment step can be easily configured within the full ETL+ pipeline that is available in Unstructured’s UI or API:
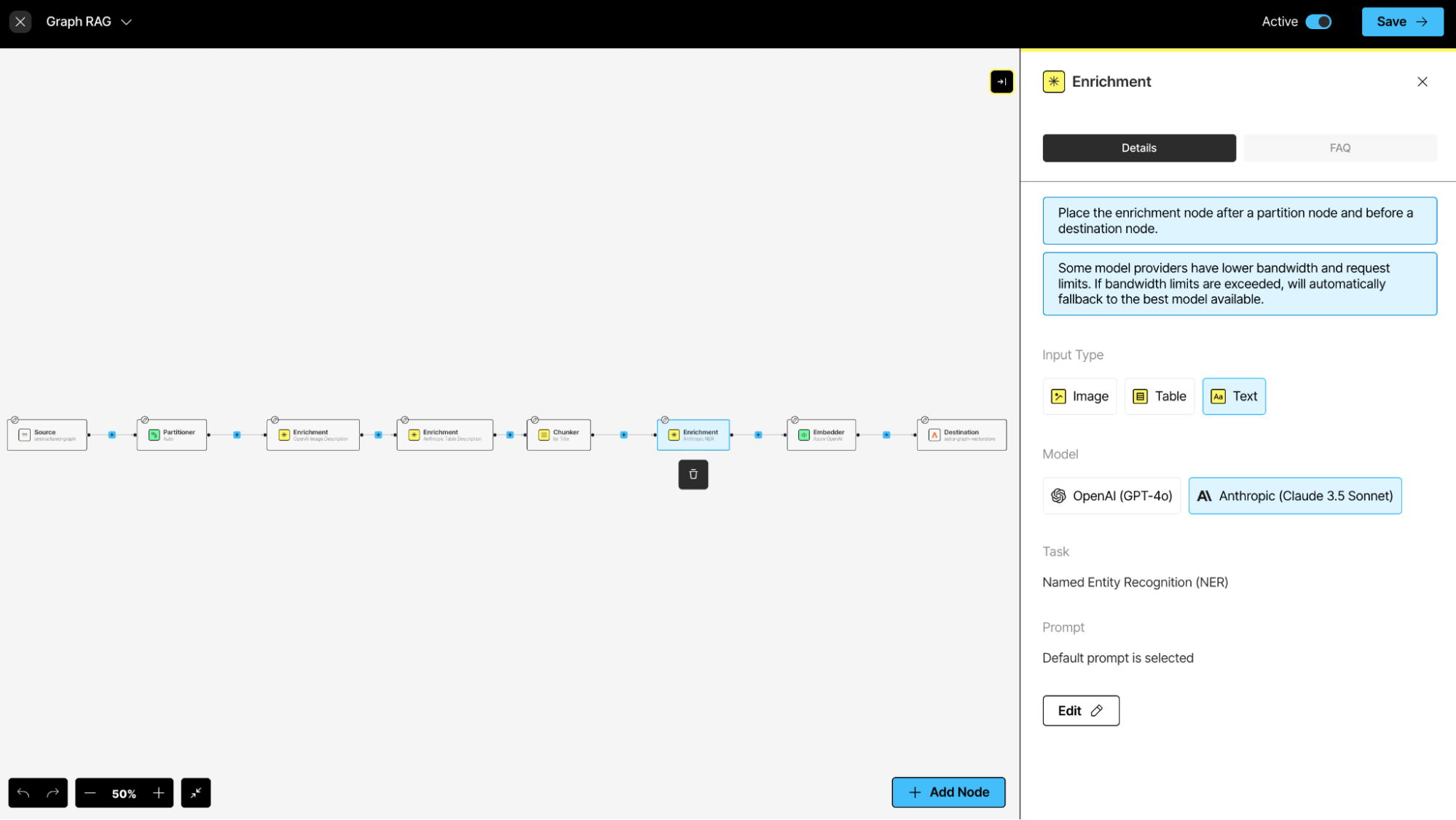
And your prompt can be customized and tested to ensure your metadata captures the entities you want extracted as well as the response format required for your knowledge graph:
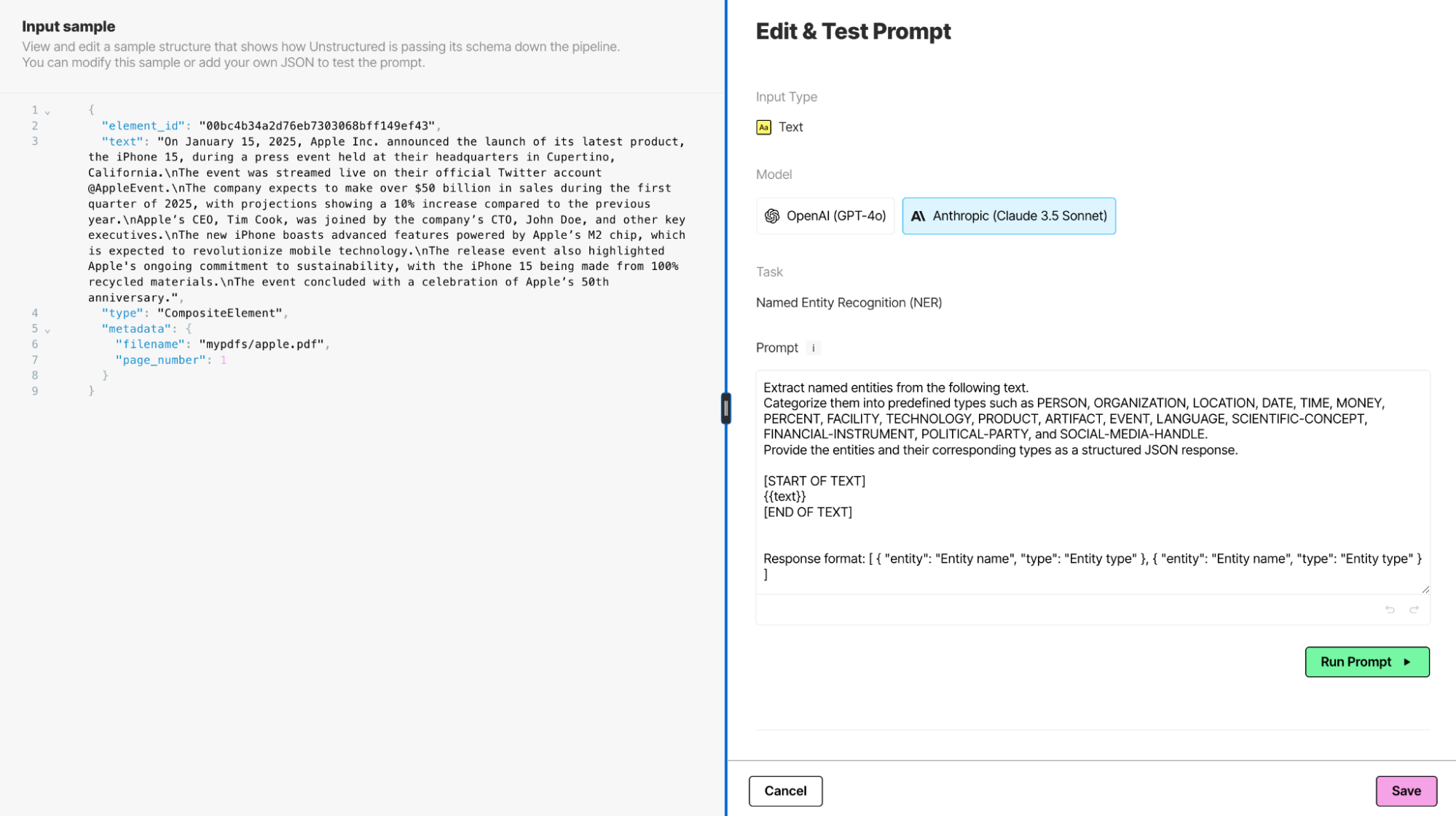
Unstructured’s declarative approach enables non-developers to build workflows by simply connecting components. This not only accelerates development but also ensures efficient execution at scale, as workflows run seamlessly on Unstructured.
Graph Retriever Library
The open source Graph Retriever library builds on LangChain vector stores, enabling dynamic graph construction from structured metadata (in this case, the metadata generated by Unstructured). It allows applications to dynamically build graphs at runtime, enhancing retrieval flexibility, context-awareness and precision without additional complex infrastructure.
Step by Step: Using Unstructured for Document Enrichment
All these steps can be accomplished with no code in the Unstructured UI by following the setup steps within the platform browser. Alternatively, we have provided a notebook with the full ETL + enrichment pipeline via Unstructured API using the Workflow Endpoint. This notebook is a precursor to the full Graph RAG flow, which assumes a workflow has already been set up. Below, we highlight a few key steps from the linked workflow creation notebook.
After setting up your credentials (see notebook), create your Astra DB destination connector:
import os
from unstructured_client import UnstructuredClient
from unstructured_client.models.operations import CreateDestinationRequest
from unstructured_client.models.shared import (
CreateDestinationConnector,
DestinationConnectorType,
AstraDBConnectorConfigInput
)
with UnstructuredClient(api_key_auth=os.getenv("UNSTRUCTURED_API_KEY")) as client:
destination_response = client.destinations.create_destination(
request=CreateDestinationRequest(
create_destination_connector=CreateDestinationConnector(
name="graphrag_astra_destination",
type=DestinationConnectorType.ASTRADB,
config=AstraDBConnectorConfigInput(
token=os.environ.get('ASTRA_DB_APPLICATION_TOKEN'),
api_endpoint=os.environ.get('ASTRA_DB_API_ENDPOINT'),
collection_name=os.environ.get('ASTRA_DB_COLLECTION_NAME'),
keyspace=os.environ.get('ASTRA_DB_KEYSPACE'),
batch_size=20,
flatten_metadata=True
)
)
)
)Then, you can create all the nodes for your workflow:
from unstructured_client.models.shared import (
WorkflowNode,
WorkflowNodeType,
WorkflowType,
Schedule
)
# Partition the content by using a vision language model (VLM).
partition_node = WorkflowNode(
name="Partitioner",
subtype="vlm",
type=WorkflowNodeType.PARTITION,
settings={
"provider": "anthropic",
"provider_api_key": None,
"model": "claude-3-5-sonnet-20241022",
"output_format": "text/html",
"user_prompt": None,
"format_html": True,
"unique_element_ids": True,
"is_dynamic": True,
"allow_fast": True
}
)
# Summarize each detected image.
image_summarizer_node = WorkflowNode(
name="Image summarizer",
subtype="openai_image_description",
type=WorkflowNodeType.PROMPTER,
settings={}
)
# Summarize each detected table.
table_summarizer_node = WorkflowNode(
name="Table summarizer",
subtype="anthropic_table_description",
type=WorkflowNodeType.PROMPTER,
settings={}
)
# Chunk the partitioned content.
chunk_node = WorkflowNode(
name="Chunker",
subtype="chunk_by_title",
type=WorkflowNodeType.CHUNK,
settings={
"unstructured_api_url": None,
"unstructured_api_key": None,
"multipage_sections": False,
"combine_text_under_n_chars": 0,
"include_orig_elements": True,
"new_after_n_chars": 1500,
"max_characters": 2048,
"overlap": 160,
"overlap_all": False,
"contextual_chunking_strategy": None
}
)
# Label each recognized named entity.
named_entity_recognizer_node = WorkflowNode(
name="Named entity recognizer",
subtype="openai_ner",
type=WorkflowNodeType.PROMPTER,
settings={
"prompt_interface_overrides": {
"prompt": {
"user": (
"Extract all named entities, including people and locations, from the given text segments "
"and provide structured metadata for each entity identified.\n\n"
'Response format: {"PLACES": ["England", "Middlesex"]}'
)
}
}
}
)
# Generate vector embeddings.
embed_node = WorkflowNode(
name="Embedder",
subtype="azure_openai",
type=WorkflowNodeType.EMBED,
settings={
"model_name": "text-embedding-3-large"
}
)Note that the `named_entity_recognizer_node` will be creating the metadata for nodes and edges, and that it is critical to place it after the chunking node, whether you are creating your workflow via UI or API.
This is the prompt that the above workflow incorporated, both specifying the types of entities to extract and the response format that will be used to construct the knowledge graph.
Extract all named entities, including people, and locations, from the given text segments and provide structured metadata for each entity identified.
Response format: {"PLACES": ["England" , "Middlesex"] }Next, after we set up the workflow, (see the workflow creation notebook for full code), we’ll run it and view the responses:
from unstructured_client.models.operations import RunWorkflowRequest
response = client.workflows.run_workflow(
request=RunWorkflowRequest(
workflow_id=info.id
)
)
print(response.raw_response)This automatically captures entities such as people (such as, "Newton") and locations ( "Woolsthorpe"), embedding them directly into structured metadata:
{
"content": "Newton was born on 25 December 1642 in Woolsthorpe, Lincolnshire, England. He died on 20 March 1726/27 in Kensington, Middlesex, England.",
"metadata": {
"type": "NarrativeText",
"element_id": "bd2de89e6b456f86e8ef09391fc3c4b9",
"metadata": {
"entities": {
"PEOPLE": [
"Newton"
],
"PLACES": [
"Woolsthorpe",
"Lincolnshire",
"England",
"Kensington",
"Middlesex"
]
}
}
}
}This structured metadata forms the basis for dynamic graph construction. And all the above can alternatively be constructed without a single line of code in the Unstructured UI.
Step by Step: Leveraging Graph Retriever for Dynamic Retrieval
The Graph Retriever library enables you to combine unstructured similarity search with structured graph traversal. Unlike a dedicated graph database, the Graph Retriever library builds on vector stores, using metadata to dynamically build connections between documents.
In the previous section we saw how Unstructured can be used to populate Astra DB with document chunks and associated metadata. With enriched metadata ready, the Graph Retriever can dynamically create graph-based retrievers. Before we build such a retriever, let’s look at how this data set can be used to build traditional RAG queries.
First, you need to specify the embedding model and initiate the vector store. Then, you can construct a basic retriever and query for information. For example, to find information about Plato:
from langchain_astradb import AstraDBVectorStore
from langchain_openai import OpenAIEmbeddings
embedding_model = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = AstraDBVectorStore(
collection_name=os.getenv("ASTRA_DB_COLLECTION"),
namespace=os.getenv("ASTRA_DB_KEYSPACE"),
embedding=embedding_model,
)
query_text = "Information about Plato"
results = vectorstore.similarity_search(query_text, k=3)
Plato
{'PEOPLE': 'Plato'}
-------------------
Plato was a philosopher in Classical Greece and the founder of the Academy in Athens, the first institution of higher learning in the Western world. He is widely considered one of the most important figures in the development of Western philosophy.
{'EVENTS': ['development of Western philosophy'],
'PEOPLE': ['Plato'],
'PLACES': ['Classical Greece', 'Athens']}
-------------------
Plato was born in 428/427 or 424/423 BC in Athens, Greece. He died in 348/347 BC in Athens, Greece.
{'DATES': ['428/427 BC', '424/423 BC', '348/347 BC'],
'PEOPLE': ['Plato'],
'PLACES': ['Athens', 'Greece']}
-------------------As you can see, this query correctly retrieved document chunks describing Plato, but notice that the results are narrowly focused on Plato. Graph Retriever enables us to retrieve a more diverse set of results, providing richer contextual information for our query.
To use the Graph Retriever, you need to specify the vector store, the edges of the graph and the search strategy. The “edges” configuration describes the graph’s schema; in this case we’ve configured the retriever to connect documents related to a given place. Similarly, the “strategy” configuration describes how the graph should be used. In this case, we start by searching for the three most-relevant documents by vector similarity, then retrieve up to 10 documents that are related to the initial three in the graph.
from graph_retriever import GraphRetriever
simple = GraphRetriever(
store = vectorstore,
edges = [("metadata.entities.PLACES", "metadata.entities.PLACES")],
strategy = Eager(k=10, start_k=3, max_depth=2)
)
results = simple.invoke("Information about Plato")
'Plato - No PEOPLE metadata'
-------------------
('Plato was a philosopher in Classical Greece and the founder of the Academy '
'in Athens, the first institution of higher learning in the Western world. He '
'is widely considered one of the most important figures in the development of '
"Western philosophy. - ['Classical Greece', 'Athens']")
-------------------
('Plato was born in 428/427 or 424/423 BC in Athens, Greece. He died in '
"348/347 BC in Athens, Greece. - ['Athens', 'Greece']")
-------------------
('Aristotle was born in 384 BC in Stagira, Chalcidice, Greece. He died in 322 '
"BC in Euboea, Greece. - ['Stagira', 'Chalcidice', 'Greece', 'Euboea']")
-------------------
('Alexander III of Macedon, commonly known as Alexander the Great, was a king '
'of the ancient Greek kingdom of Macedon and a member of the Argead dynasty. '
'He was born in Pella in 356 BC and succeeded his father Philip II to the '
'throne at the age of 20. He spent most of his ruling years on an '
'unprecedented military campaign through Asia and northeast Africa, and by '
'the age of 30, he had created one of the largest empires of the ancient '
"world, stretching from Greece to northwestern India. - ['Macedon', 'Pella', "
"'Asia', 'northeast Africa', 'Greece', 'northwestern India']")
-------------------
('Philip II was born in 382 BC in Pella, Macedon. He was assassinated in 336 '
"BC in Aegae, Macedon. - ['Pella', 'Macedon', 'Aegae']")
-------------------
('Philip II of Macedon was the king of the ancient Greek kingdom of Macedon '
'from 359 BC until his assassination in 336 BC. He was a member of the Argead '
"dynasty and the father of Alexander the Great. - ['Macedon', 'Greek']")
-------------------
('Philip II is credited with transforming Macedon into a powerful military '
'state. He reformed the Macedonian army, introducing the phalanx infantry '
'corps, and expanded his kingdom through both diplomacy and military '
'conquest. His reign laid the groundwork for the future conquests of his son, '
"Alexander the Great. - ['Macedon']")
-------------------
('Alexander was born on 20 July 356 BC in Pella, Macedon. He died on 10/11 '
'June 323 BC in the Palace of Nebuchadnezzar II, Babylon, Mesopotamia '
"(modern-day Iraq). - ['Pella', 'Macedon', 'Palace of Nebuchadnezzar II', "
"'Babylon', 'Mesopotamia', 'Iraq']")
-------------------The results now include supporting information about where Plato was born and lived. This second set of documents includes documents related to the first set of documents through shared locations, but we can change the structure of the graph by simply creating a new retriever configured to use different metadata. For example, we could follow connections based on shared people rather than places:
by_people = GraphRetriever(
store = vectorstore,
edges = [("metadata.entities.PEOPLE", "metadata.entities.PEOPLE")],
strategy = Eager(k=10, start_k=3, max_depth=2)
)
results = by_people.invoke("Information about Greece")The Graph Retriever library enables the creation of many different types of graph structures and provides a rich set of graph traversal operations. It is also very easy to redefine graph edges and schemas; as long as the relevant metadata is available, we can simply reconfigure the GraphRetriever with the new schema or strategy and proceed without any additional data loading or overhead computation. The edge definitions and traversal strategies are then applied at query time. And, if using graph RAG as part of an agentic workflow, this reconfiguration process is simple enough that the appropriate graph schema could even be selected by an AI agent on a per-query basis.
Conclusion
Modern tools like Unstructured and the Graph Retriever library have lowered barriers to implementing graph-based RAG applications. These technologies automate and streamline complex graph construction tasks, eliminate traditional infrastructure demands and offer dynamic retrieval capabilities that are flexible and powerful.
With these advancements, graph-based retrieval is accessible, intuitive, and ready to significantly enrich your retrieval-based AI applications.




