Retrieval-augmented generation (RAG) fundamentals
This guide steps through how to harness knowledge graphs in retrieval-augmented generation to add a level of contextual understanding.
Graph RAG removes the limitations of traditional vector search, seamlessly integrating multiple data sources to produce more accurate results. Industry leaders are pushing the boundaries of AI with graph RAG and depending on Astra DB to implement this evolution.
Let's walk through how.
What is RAG and how it works
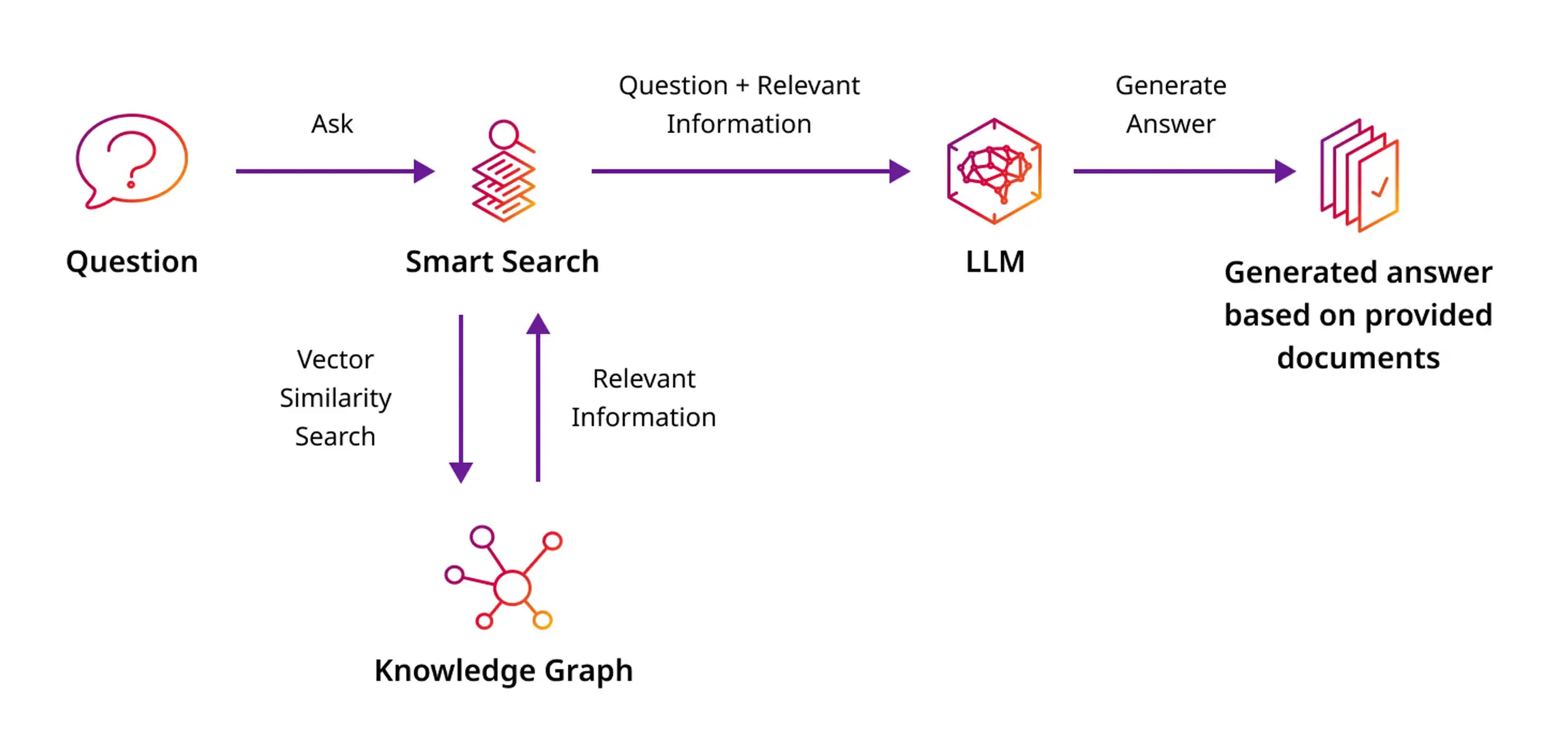
RAG is a natural language querying approach for enhancing existing large language models (LLMs) with external knowledge. RAG includes a retrieval information component that fetches additional information from an external source, known as “smart context”, to retrieve information and answer questions with higher accuracy.
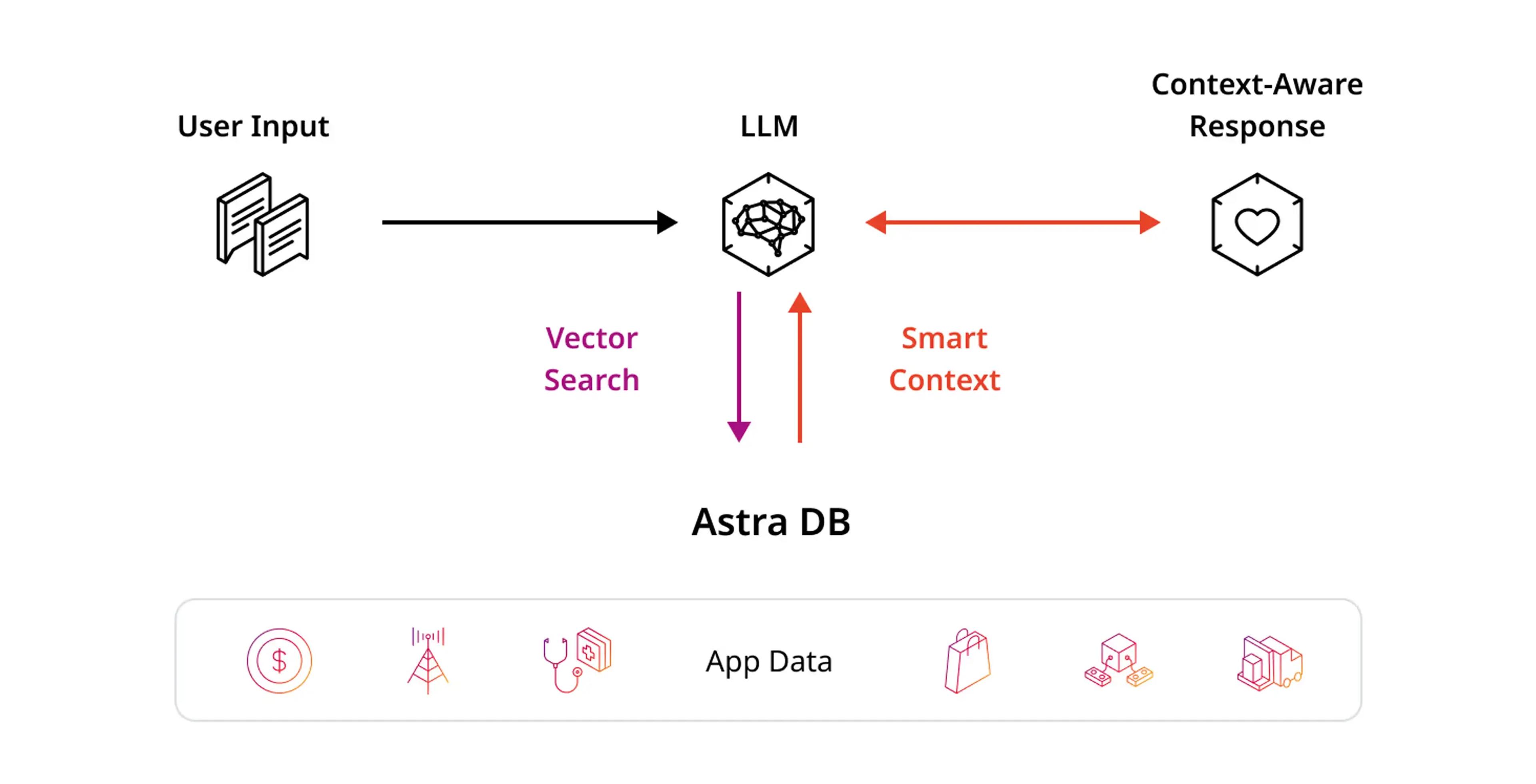
GenAI has to get real with business data, not just build a better search engine. To date chatbots only used the first type of data - the user input. Basic RAG adds in the second type of data - unstructured. Smart context needs all four types of data – user input, unstructured, semi-structured, and structured – in real time.
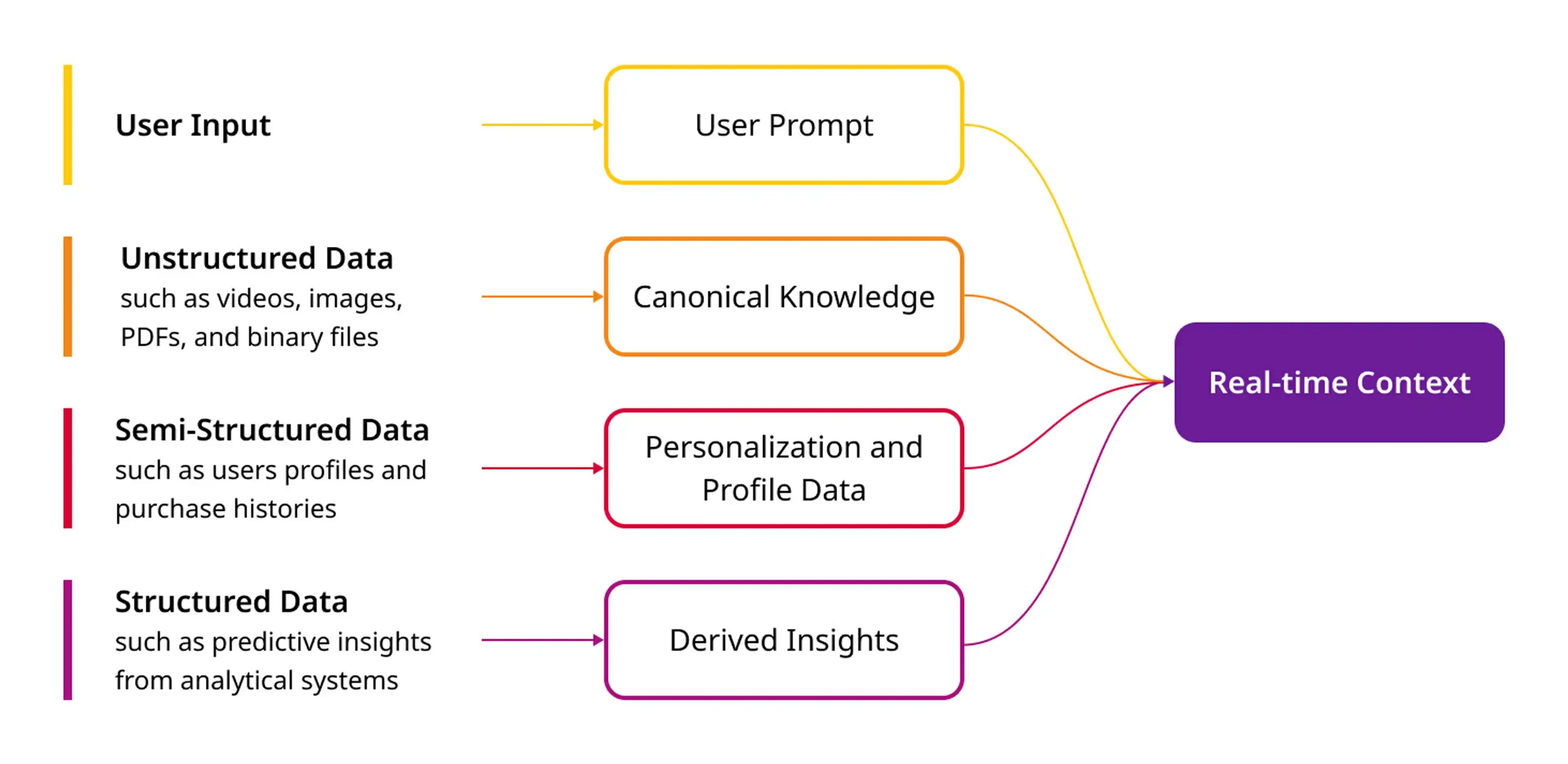
Canonical knowledge comes from unstructured domain-specific data which is currently stored within internal content, collaboration, and search systems. These are videos, images, PDFs, binaries, and other files which are also referenced as metadata from transactional systems.
Personalization and profile data are incorporated from semi-structured data representing information about users and their interactions with the Enterprise. For example, users profiles, purchase histories, reviews, questions, clicks, authentications, and other interactions.
Derived insights are built from structured historical and predictive insights which are the output of analytical systems. For example, predicted products of interest or probability of churn.
What is graph RAG?
Graph RAG is an enhancement to the retrieval-augmented generation (RAG) approach. It retrieves a knowledge graph as grounding context to provide to a large language model (LLM) for generation.
Graph RAG generally retrieves a knowledge graph and then uses a large language model (LLM) to generate a response. A knowledge graph can be either entity-centric or content-centric. Regardless of the format chosen, you don’t need a dedicated graph DB to implement graph rag.
What is a knowledge graph?
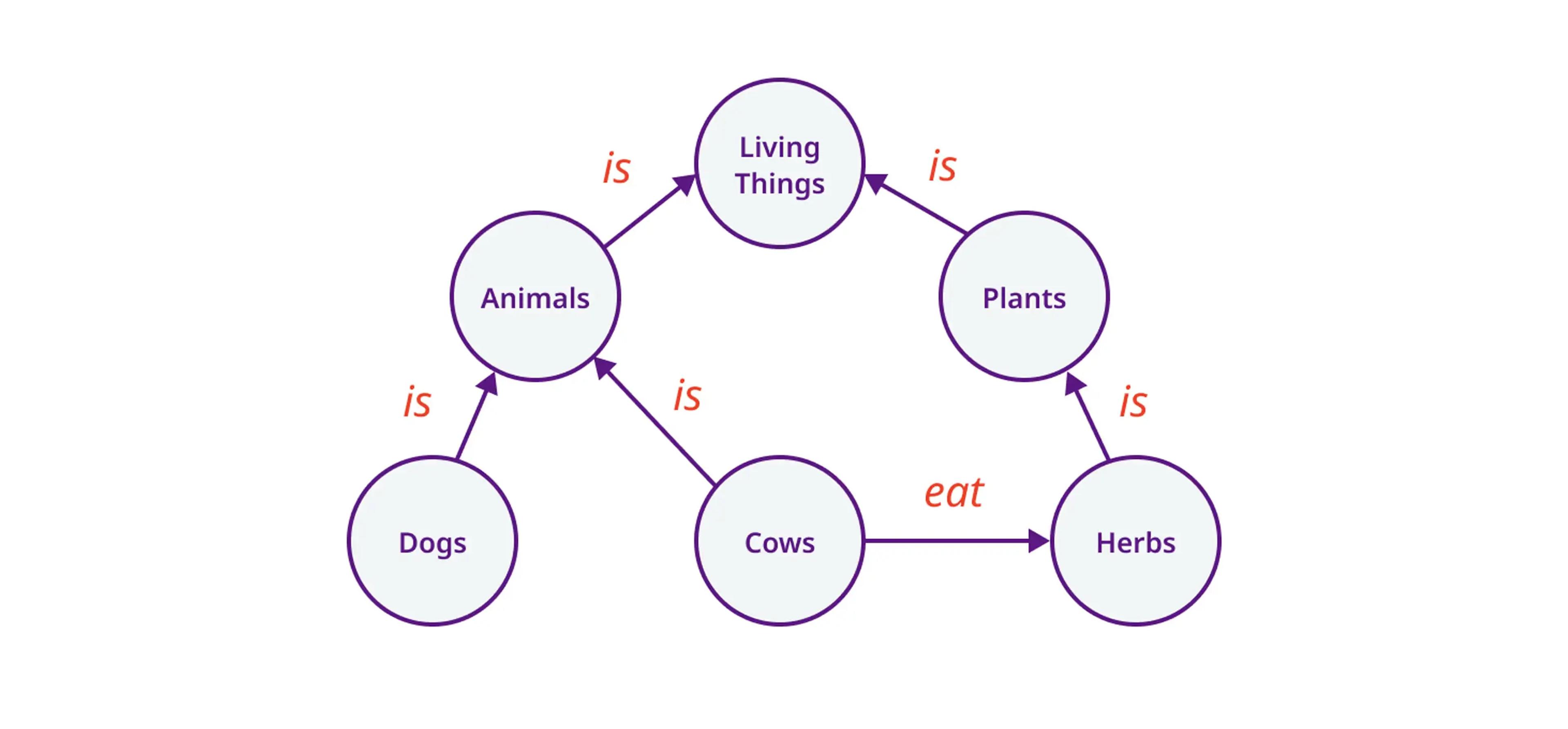
Knowledge graphs are specific types of graphs where nodes represent concepts and edges represent the relationships between those concepts. This method allows for more structured and contextually rich information to be incorporated into the generated text, improving the LLM responses' accuracy and relevance.
A more simplified version of entity nodes and relationship edges is shown below. When vector search falls short in RAG, relating knowledge can be the answer.
However, knowledge graphs can be either entity-centric or content-centric. No matter which format you choose, you don’t need a dedicated graph DB to implement graph RAG. Content-centric knowledge graphs are purpose-built for graph RAG and provide better LLM integration and relevancy.
Entity-centric knowledge graphs vs. content-centric knowledge graphs
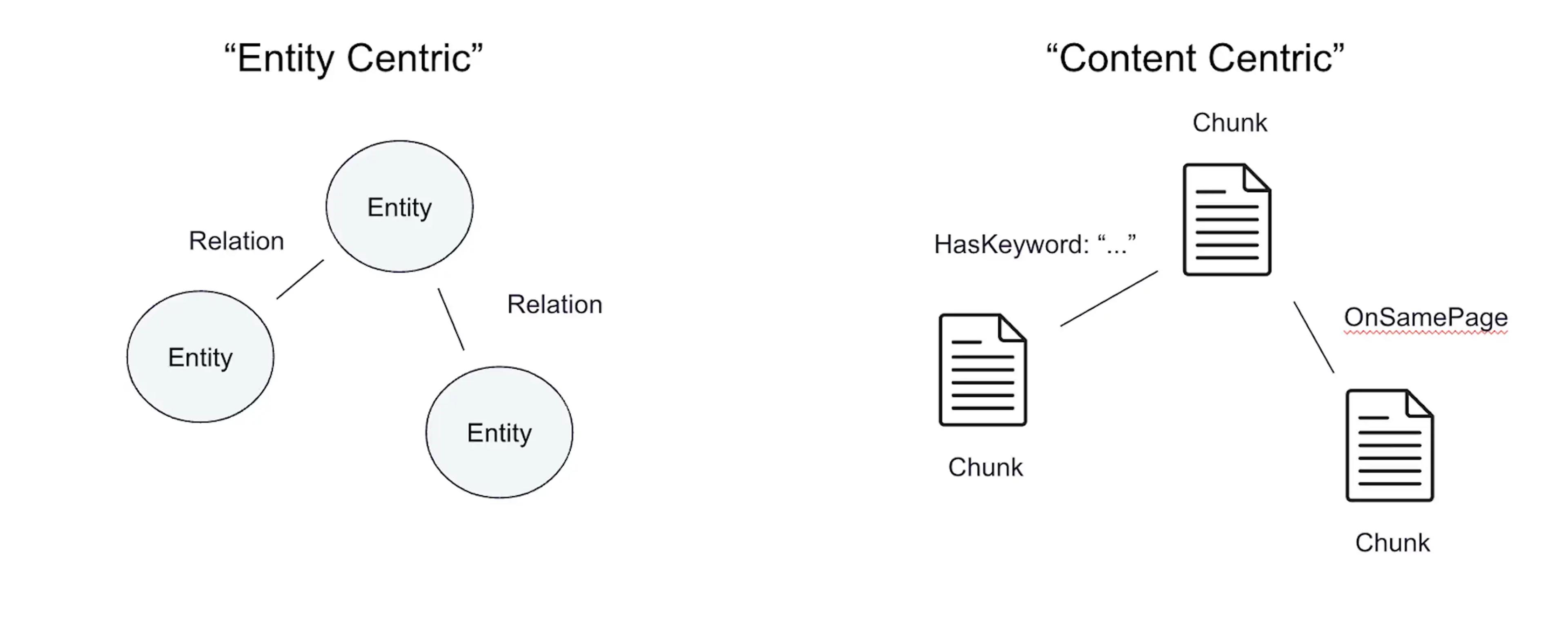
An entity-centric knowledge graph allows for a variety of queries to be expressed using a graph query language like Cypher or Gremlin. The knowledge graph captures relationships between information that vector similarity search would miss, and large language models (LLMs) make it possible to extract knowledge graph triples (source, relationship, target) from unstructured content with only a prompt.
With a content-centric knowledge graph, you start with nodes representing content (chunks of text, for example) instead of entities. The nodes of the graph are exactly what is stored when using vector search. Nodes may represent a specific text passage, an image or table, a section of a document, or other information. These represent the original content, allowing the LLM to do what it does best - process the context and pick out the important information.
Content-centric knowledge graphs are generally a better fit for graph RAG. Content-centric knowledge graphs are specifically designed for graph RAG and provide better integration with LLMs, giving you control over structured "links" between chunks stored in a vector database.
This approach enables a more comprehensive contextual understanding that leads to more cost-effective, intelligent, and precise generation. You can use more types of existing data than vector embeddings alone, such as how documents hyperlink to each other.
Astra DB supports both entity-centric and content-centric knowledge graphs.
Benefits of graph RAG
Graph RAG brings two key pieces to RAG:
- Enhanced contextual understanding: LLMs can better understand the relationships and dependencies between different pieces of information. This leads to more coherent and contextually appropriate generated responses.
- Improved knowledge integration: Graph RAG can integrate information from multiple sources, including knowledge graphs and external databases, allowing the model to generate more accurate and informed responses.
For example, if your vector database contains the content you need but it wasn’t retrieved, you can add an edge to link the relevant documents. This results in deeper insights and more accurate results by incorporating new sources of structured data.
Best practices for mastering graph RAG
Best practices for mastering graph retrieval-augmented generation (RAG) involve several key strategies.
- First, use content-centric knowledge graphs to capture information about how content in your domain or business relates to each other. This approach helps in creating a more comprehensive and interconnected dataset.
- Second, choose the right database for your use case, especially if you’re building an AI application with real-time user interaction where efficient query time is crucial. If your application needs to insert new data quickly to make it immediately available for retrieval, efficient data ingestion is essential.
Astra DB supports vector, graph, and graph+vector data types, providing simultaneous efficient ingestion and query capabilities at scale. This ensures that your system can handle large volumes of data while maintaining performance and accuracy.
Limitations of vector search
When does vector similarity fall short? When many vectors are too close in the vector space, or related content is too far.
Traditional search enhancement techniques often fall short when it comes to complex queries and the high demand brought by cutting-edge technologies like ChatGPT. They cannot understand the relations between entities and retrieve relevant information. See the below diagram illustrating an example.
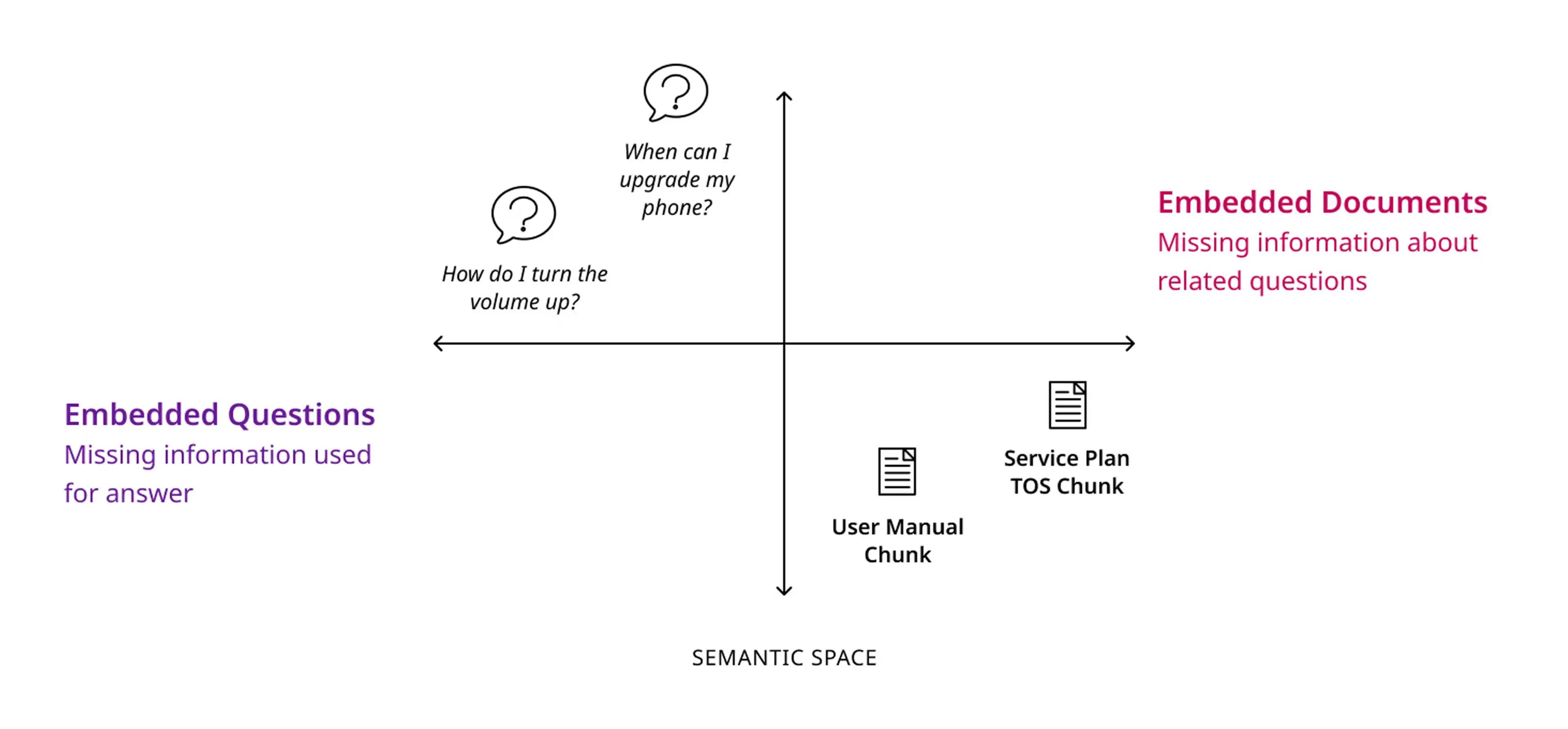
Questions are often semantically “far from” their answers in vector space leading to incomplete context being retrieved for an LLM to generate an answer. There are hundreds of supported cellular devices on any carrier’s website, to ensure the right information is retrieved more than a simple vector search is needed.
Limitations of traditional entity-centric knowledge graphs for RAG
Entity-centric knowledge graphs, while powerful for executing graph queries, have several limitations when applied to retrieval-augmented generation (RAG). These graphs require a labor-intensive process to create the schema and guide the model to the right knowledge extraction, necessitating domain expertise.
Although large language models (LLMs) can assist, applying them during ingestion is costly. Scaling entity-centric knowledge graphs and achieving good results is challenging.
Additionally, building these graphs occurs before the questions are known, leading to speculation and human guidance on which facts are important. This process results in extracting only entity and relationship information, potentially discarding other information that might be crucial for the LLM to generate accurate responses.
How Astra DB overcomes vector search limitations
Astra’s graph RAG addresses the challenges of traditional entity-centric knowledge graphs by leveraging content-centric knowledge graphs, which are purpose-built for generative AI applications that require full context retrieval. These graphs store both structured and unstructured text within a single database. This significantly reduces the effort to provide the necessary information to your large language model (LLM).
One of the key advantages of content-centric knowledge graphs is that they preserve the original content within the nodes, ensuring that no information is discarded during the creation process. This approach minimizes the need to re-index information as requirements evolve, allowing the LLM to extract answers from the preserved context based on the specific question.
Additionally, the creation of these graphs does not require domain experts to tune the knowledge extraction process. Instead, you can add edge extraction based on keywords, hyperlinks, or other data properties to your existing vector search pipeline, with links being automatically added. You can further simplify this process by leveraging our pre-built extractors to define graph connections and load documents quickly.
You can implement the creation process for content-centric knowledge graphs using straightforward operations on the content. That eliminates the need to invoke an LLM to create the knowledge graph.
With our GraphVectorStore contribution to LangChain, users can easily build a vector store with graph connections through a simple two-line code change. This integration makes it easy to enhance the performance of RAG applications by combining the connectivity of graphs with the ability to understand and retrieve relevant data efficiently.
Handling highly connected knowledge graphs
Handling highly-connected knowledge graphs can be challenging, but Astra DB’s content-centric knowledge graphs offer a solution that is both fast and easy to populate, similar to vector stores. However, the generation of highly connected graphs necessitates careful consideration of when and how links or edges are managed.
Astra addresses this by storing information about what each chunk links to, enabling the scalable and efficient storage of graphs with arbitrarily high connectivity. This approach ensures that even highly connected graphs can be managed without performance degradation.
Traversal within these graphs is guided by maximum-marginal relevance (MMR), which allows for the retrieval of the most relevant and diverse information related to a query. This method ensures that the graph traversal process yields comprehensive and pertinent results, enhancing the overall effectiveness of the knowledge graph in providing accurate and contextually rich answers.
More efficient knowledge graphs without edges
Building more efficient knowledge graphs without edges involves optimizing the schema and query patterns for retrieval on top of a general-purpose database. This approach reduces the complexity of adding nodes and enables faster traversals.
The key change is to store the outgoing and incoming links rather than materializing the edges. This means that traversal happens at query time to discover the edges rather than when loading nodes, which allows for even faster traversals.
By considering each tag connecting nodes once during the traversal, the set of reached nodes doesn't change, unlike in a conventional graph where every edge between nodes needs to be considered. This method leverages the efficiency of a general-purpose database to handle inter-connected content effectively.
Links and edges
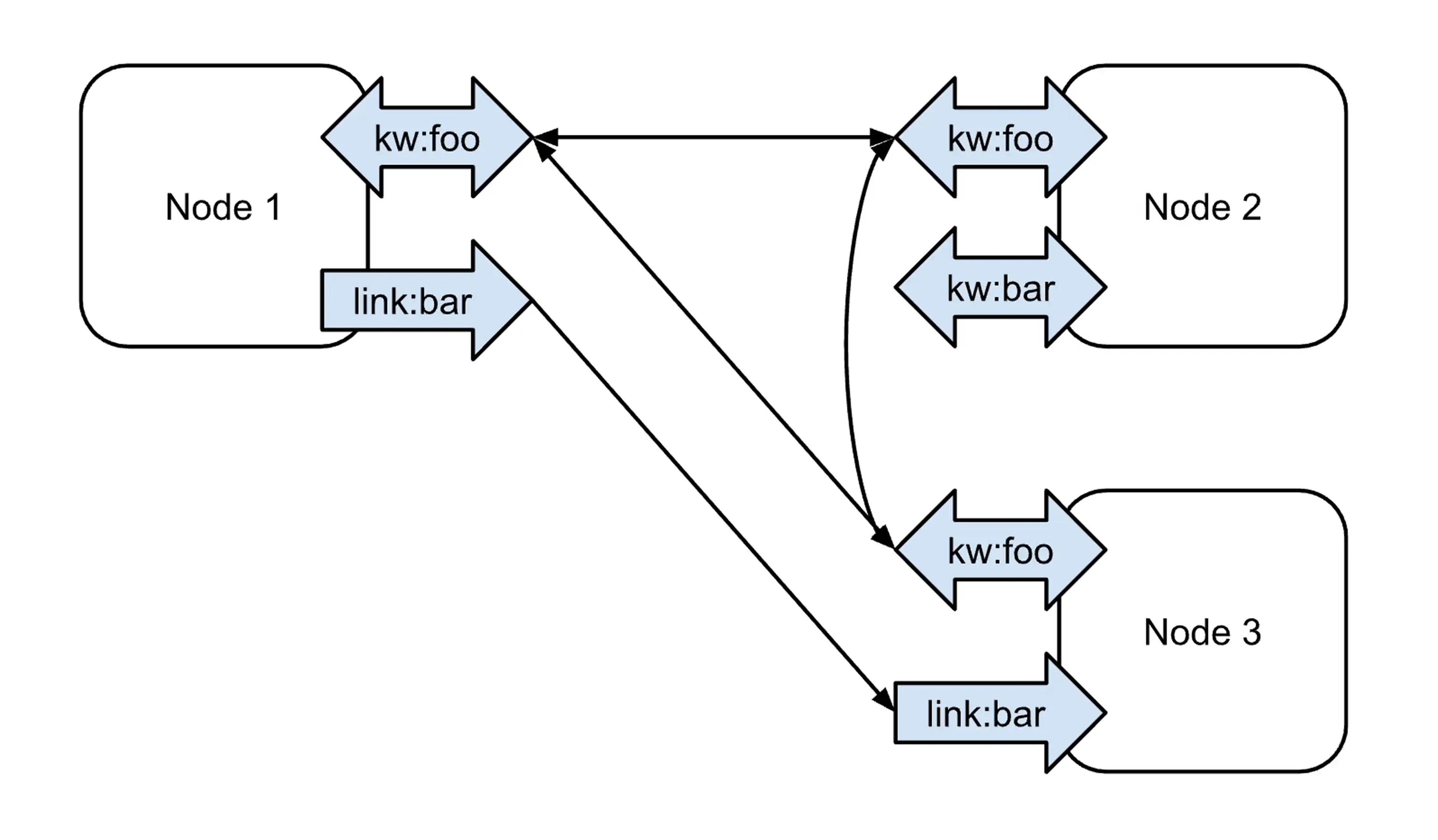
Rather than describing the edges specifically, we use the concept of "links", see the diagram below to visualize the concept.
Each node defines zero or more links that connect to corresponding links on other documents. A node with an outgoing link has an edge to every node with a matching incoming link.
For example, consider three nodes linked together with a common keyword, "foo." Node 2 is the only node with the keyword "bar," so it has no edges for that kind/tag. Node 1 has an outgoing link to "bar," and node 3 has an incoming link, so they are connected with a directed edge.
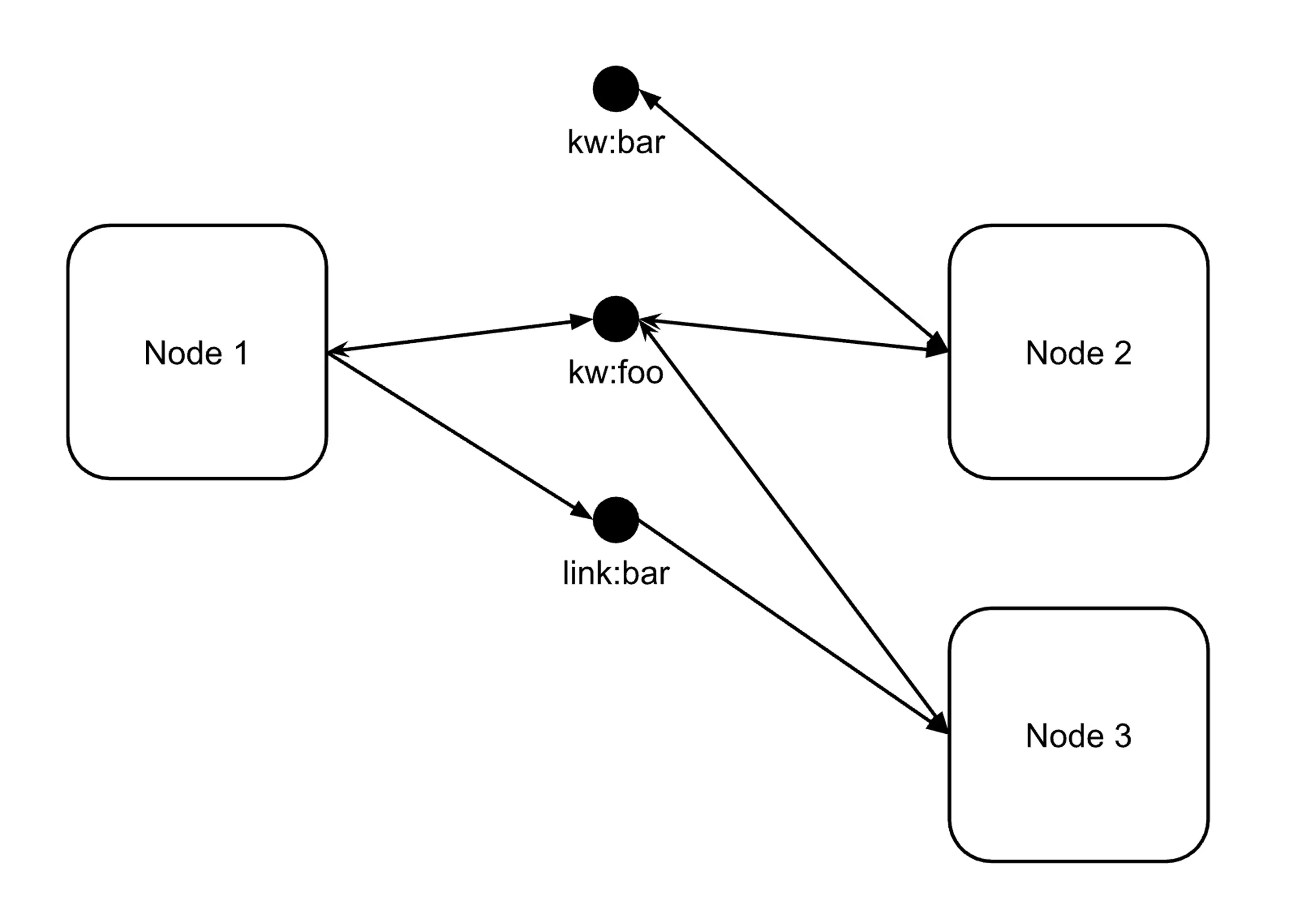
Similar to how a hypergraph can be represented as a bipartite graph, this can be visualized as a graph where edges between nodes pass through a different kind of node representing the tag seen in the diagram below. In this case, an outgoing link is an edge from a node to the tag, and an incoming link is an edge from a tag to the node. An edge between nodes in the original graph is the same as a length 2 path between nodes passing through a tag-node in this bipartite graph. A length 2 path would be any path between nodes including exactly two edges.
Future directions for graph RAG development
Future directions for graph RAG development include several key areas of focus:
- Manual linking with automatic extraction: Simplifying the process of manual linking by incorporating automatic extraction techniques.
- Multimodal links: Developing capabilities to link different types of content, such as paragraphs to tables or images that they reference.
- Document definition linking: Enhancing the ability to link specific terms or phrases within documents, such as "the tenant" in legal documents.
- Natural language reference detection: Implementing systems to detect and link natural language references like "see section 4" or "as defined...".
- Citations: Improving the handling and linking of citations within documents.
- Hybrid knowledge graph support: Supporting both content-centric and entity-centric knowledge graphs.
- Re-ranking based traversals: Introducing additional traversal methods that re-rank nodes based on specific criteria.
- Summarization: Developing techniques to summarize the neighborhood of each node and/or community within the graph.
These directions aim to enhance the efficiency, accuracy, and usability of graph RAG systems, making them more robust and versatile for various applications.
Get started with Astra DB for full context retrieval
Astra DB provides the connectivity of graphs, allowing you to deeply understand your data and manage outliers effectively when they arise.
To get started with Astra DB for full context retrieval, you can leverage its built-in support for this approach right out of the box. We invite you to integrate content-centric knowledge graphs into your projects using LangChain. This integration will enable you to explore further enhancements in connecting and retrieving content, making your data interactions more efficient and insightful.
