As applications like DALL-E show, generative AI can do far more than generate text. Companies are employing multimodal AI and GenAI to create everything from marketing videos to enhancing manufacturing design processes.
GenAI apps built using a combination of large language models (LLMs) and retrieval-augmented generation (RAG) can use multimodal GenAI to support these use cases and more. In this article, we’ll explore the basics of supporting multimodal GenAI using multimodal vector database retrieval for RAG, including how to store and search multimodal content in a vector database.
Multimodal vector database basics
Multimodal AI is AI that incorporates visual aspects like images and video, and integrates audio aspects like speech recognition or synthesis. Like text assets such as document, it relies on vector embeddings to find related context for a given query.
Incorporating a multimodal vector database into a GenAI app workflow requires three components:
- Input: Standardizes multimodal objects into a common format (e.g., a textualtextal description of its contents)
- Fusion: Combines information from various input modalities to create a unified representation
- Output: Leverages the generative abilities of an LLM to curate the fused components into the specified output format - text, audio, or video
Implementation multimodal RAG
RAG is a technique for adding additional detailed instructions to an LLM query. It supplements the LLM’s general knowledge with domain-specific information relevant to your use case - e.g., product manuals or past support chat transcripts for a customer support chatbot query.
To support multimodal RAG, then, you need both:
- An LLM capable of multimodal output, such as OpenAI GPT-4V, Google Gemini, and Claude 3.5 Sonnet
- A vector database (or graph database, etc.) capable of creating, storing, and searching multimodal embeddings
Use cases for multimodal vector database retrieval
Adding multimodal vector database retrieval to your GenAI toolkit means you can support a variety of new traditional AI and GenAI scenarios, including:
- Creating a new promotional video for a product based on product information, images, and past marketing assets
- Recommending products based on an uploaded image
- Analyzing voice patterns in a call to detect customer frustration and change the type of advice being offered or customer support tactics being used
- Creating content for employee training
- Improved anomaly detection - e.g., detecting potential issues with manufacturing machine tolerances based on analyzing video and audio of the equipment
- Performing semantic search over not just text, but video and audio content
Challenges with a multimodal vector database
The key challenge with multimodal vector database retrieval is creating a unified format for storage, search, and retrieval.
Multimodal assets can span a number of different media types - MPEGs, AVIs, PDFs, JPEGS, GIFs, etc. - each with their own data points and nuances to capture. A unified representation needs to be able to capture data from all of these varied types to create a single, useful representation.
Multiple models and systems exist for representing, e.g., images in a common format. Examples include Microsoft’s Florence-2 and OpenAI’s CLIP. These systems aim to improve upon traditional deep learning approaches to computer vision, which are typically only good at a single task and require significant time and effort to train to a different task. By contrast, models like Florence-2 and CLIP focus on zero-shot learning, which aims for high accuracy absent pre-training.
Multimodal vector database retrieval how-to: Building a multimodal search app
Fortunately, with the right database and tools, implementing multimodal vector database retrieval can be accomplished in a few basic steps.
Astra DB is a serverless vector database that supports generative UI use cases instantly at scale. Using Astra DB, you can support context-sensitive searches across diverse data formats, including text (structured, semi-structured, and unstructured), images, and audio.
Astra DB works seamlessly with LangChain, a framework for building production-ready GenAI applications. Available for both Python and JavaScript, LangChain condenses connecting (“chaining”) the different components of an application using a simple syntax.
Using Astra DB, LangChain, and Google Gemini, you can quickly add multimodal vector database retrieval to your RAG-enabled LLM apps. Let’s see how to get started below.
You can find the code and more advanced steps for this walkthrough in the workshop-rag-fashion-buddy repository on GitHub. Fork the above repository into your own account before proceeding.
Create Astra DB account and database
If you don’t already have an Astra DB account, you can sign up for one for free. You can sign in using your Google or GitHub accounts. (Note: If you use GitHub, you’ll have to set a public email address on your GitHub account.)
Once signed in, you should be on the Astra DB page by default. Select Databases and then select Create Database. (Don’t worry about getting charged for this tutorial - DataStax provides a free $25 monthly credit for development and learning.) Create a serverless vector database with a Database name of langchain4j. For Region, select the AWS region closest to you.
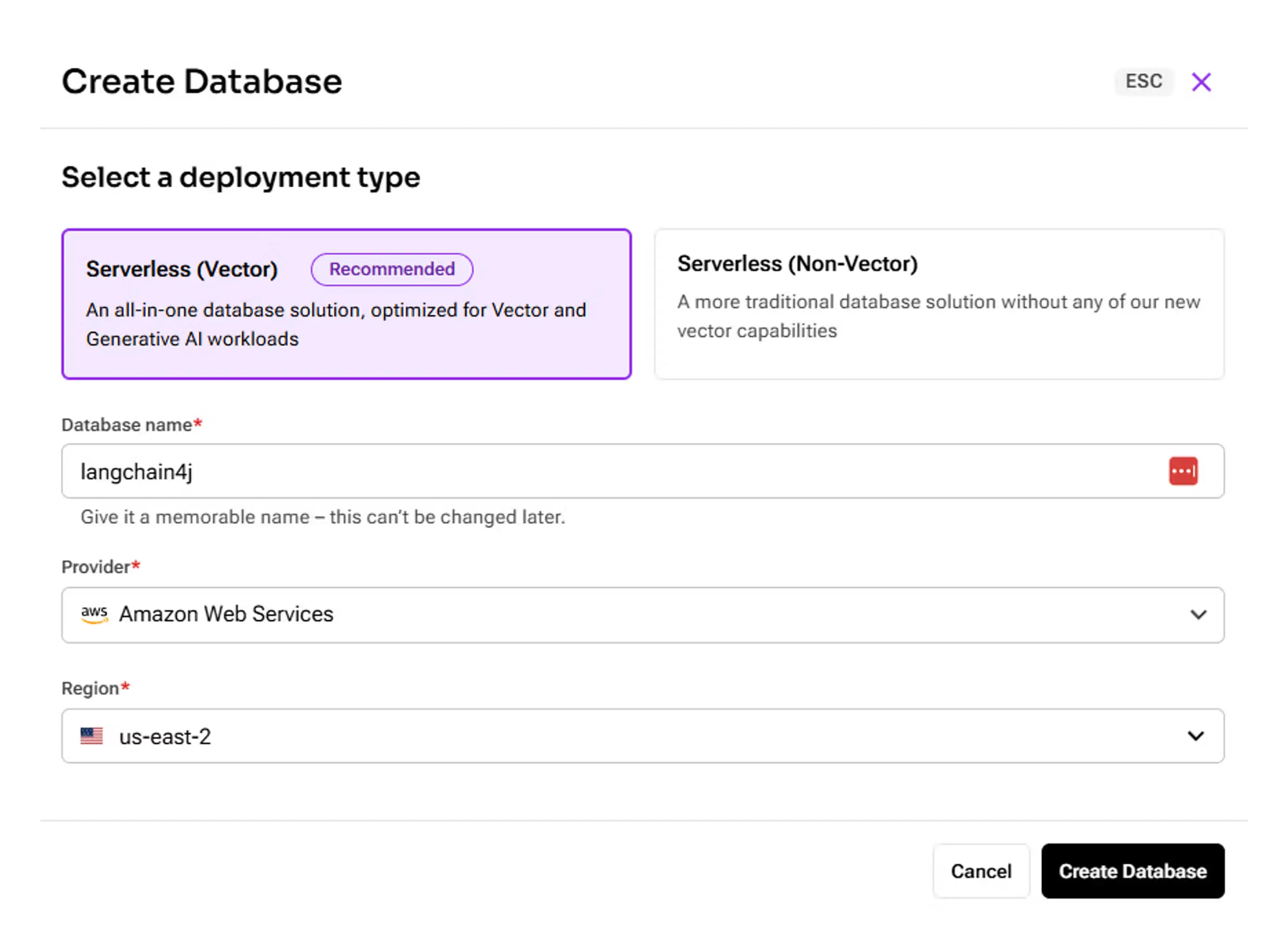
Next, select Create Database. Wait until your database finishes initializing before proceeding.

Finally, copy the API Endpoint on the right-hand side to a text file. Additionally, select Generate Token and select your API token. You’ll use these values to connect to your database.
Create Google Cloud Vertex AI account
Next, open Google Cloud Platform. If you don’t have an account, sign up and start a free trial to receive USD $300 in credits.
In GCP, in the left-hand corner, select Select a project and then select NEW PROJECT. Name it rag-workshop-datastax, and then select CREATE.

Once the project finishes creating, select the project drop-down in the upper left-hand corner again. Next to rag-workshop-datastax, select the project ID and copy it into a text window. You’ll use this value below.

Next, in the Search dialog at the top of the page, enter Vertex AI and select the service. Vertex AI is GCP’s fully-managed unified AI development platform for GenAI apps. Once in Vertex AI, find Vertex AI Studio and select Try now.

In the Get started with Vertex AI Studio prompt, select Agree and continue.
Run multimodal searches in Astra DB
Finally, let’s import some data into Astra DB and run some searches on it. We’ll do all of this using Google Colab, GCP’s hosted Jupyter Notebook service.
Open the Jupyter notebook here in a separate tab and run the first few sets of commands - Install Python Dependencies and Import Packages. Next, run Load Astra DB and Vertex AI credentials, which will prompt you in succession to enter the three values that you copied earlier:
- Your GCP project ID
- Your Astra DB endpoint
- Your Astra DB access token
After pasting in one, press ENTER to enter the next.
Once done, run Configure Google Vertex AI Credentials and Google Colab to sign in to GCP via Colab. Confirm all of the prompts to enable Colab to access the resources required in your GCP account.
Next, we’ll load the Zara Clothing dataset from HuggingFace. This requires creating a HuggingFace account and generating an API token. You can log in or create an account here and then generate an access token with Write permissions from the Access Tokens page. (If you’re creating a new account, confirm your e-mail address first in order to generate a token.)

To set this token, create a new code block in the Colab notebook (+ Code in the common strip below the menu) and run it, then enter your HuggingFace token into the window when prompted:
os.environ["HF_TOKEN"] = getpass.getpass("Provide your HF_TOKEN:")
Next, run the code in Read in Zara Clothing dataset to read in the data:
from datasets import load_dataset
dataset = load_dataset("datastax/zara_embeddings_newcategories", split='train')Run the next block to convert these embeddings into an array of vectors:
df = pd.DataFrame.from_dict(dataset) df['embeddings'] = df['embeddings'].apply(json.loads) # converts embeddings into an array of vectors
Then, run the df.head() command to see how the data is shaped:

Now run the code in Use Vertex AI multimodal to create embeddings. This code sets some variables that you’ll use later in this walkthrough.
After this, run the next two code blocks to load all 936 entries into your Astra DB instance. The first call will connect to your Astra DB and create a new collection called fashion_buddy_workshop:
from astrapy.db import AstraDB, AstraDBCollection # Connect to our vector database astra_db = AstraDB( token=os.environ["ASTRA_DB_TOKEN"], api_endpoint=os.environ["ASTRA_DB_ENDPOINT"]) # Creating new collection collection = astra_db.create_collection( collection_name="fashion_buddy_workshop", dimension=1408)
Next, run the second block to import the records:
from ipywidgets import IntProgress
from IPython.display import display
# Load to vector store
def load_to_astra(df, collection):
len_df = len(df)
f = IntProgress(min=0, max=len_df) # instantiate the bar
display(f) # display the bar
for i in range(len_df):
f.value += 1 # signal to increment the progress bar
f.description = str(f.value) + "/" + str(len_df)
# Store columns from pandas dataframe into Astra
product_name = df.loc[i, "product_name"]
link = df.loc[i, "link"]
product_images = df.loc[i,"product_images"]
price = df.loc[i, "price"]
details = df.loc[i, "details"]
category = df.loc[i, "category"]
gender = df.loc[i, "gender"]
embeddings = df.loc[i, "embeddings"]
try:
# add to the Astra DB Vector Database using insert_one statement
collection.insert_one({
"_id": i,
"product_name": product_name,
"link": link,
"product_images": product_images,
"price": price,
"details": details,
"category": category,
"gender": gender,
"$vector": embeddings,
})
except Exception as error:
# if you've already added this record, skip the error message
error_info = json.loads(str(error))
if error_info[0]['errorCode'] == "DOCUMENT_ALREADY_EXISTS":
print("Document already exists in the database. Skipping.")
load_to_astra(df, collection)Finally, you can query your database! There are a few examples given in the Colab notebook.
For fun, save the following image to your local hard drive:

Run the code defined in Define functions for providing product recommendations, which defines some helpful but simple code to perform searches on your Astra DB database.
Now, run the first example, Query from file upload (without categories), and supply the image you just saved as an argument:
from google.colab import files uploaded = files.upload()
Now, run a similarity search using the image you just uploaded:
reference_image = "mohammad-faruque-muWowSks60w-unsplash.jpg" find_similar_items(reference_image)
You should receive a list of results, which includes a list of products in the Zara catalog that resemble the uploaded image. Click on the returned URLs and check them out for yourself!

Next steps
With these steps, you can set up and fine-tune your multimodal RAG implementation until it’s working the way you expect. You can walk through the rest of the workshop-rag-fashion-buddy demo to deploy a LangChain-powered app that provides a user-friendly UI to your backend GenAI chain.
The TL;DR here: adding multimodal capabilities to your GenAI applications doesn’t have to be hard. With tools like LangChain and Astra DB, you can create and deploy a solution that’s accurate, reliable, and scalable.
